








SQL Essentials Training & Certification
- 11k Enrolled Learners
- Weekend/Weekday
- Self Paced
(4250)
There is no place where Data does not exist! In today’s market, around 2.5 quintillion bytes of data gets generated every day. So, it is very important for all of us to analyze this data and generate the required results by using the database management systems(DBMS). Well, knowing DBMS opens the doors for you to Become a Database Administrator. I believe that you are already aware of these facts and this has made you land on this DBMS Interview Questions article.
In this article on DBMS Interview Questions, I will be discussing the top questions related to DBMS asked in your interviews. These questions are segregated to generic, SQL-based, and query-based. These are collected after consulting with people having excellent skills in this field.
For your better understanding, I have divided the article into the following sections:
| DBMS | RDBMS |
| Provides an organized way of managing, retrieving, and storing from a collection of logically related information | Provides the same as that of DBMS, but it provides relational integrity |
A software application that interacts with databases, applications, and users to capture and analyze the required data. The data stored in the database can be retrieved, deleted and modified based on the client’s requirement.
The different types of DBMS are as follows:
The advantages of DBMS are as follows:
The different languages present in DBMS are as follows:
Query optimization is the phase that identifies a plan for evaluation query that has the least estimated cost. This phase comes into the picture when there are a lot of algorithms and methods to execute the same task.
The advantages of query optimization are as follows:
A NULL value is not at all same as that of zero or a blank space. The NULL value represents a value which is unavailable, unknown, assigned or not applicable whereas zero is a number and blank space is a character.
There are three levels of data abstraction in DBMS. They are:
It is a diagrammatic approach to database design, where you represent real-world objects as entities and mention relationships between them. This approach helps the team of DBAs’ to understand the schema easily.
A relationship in DBMS is the scenario where two entities are related to each other. In such a scenario, the table consisting of foreign key references to that of a primary key of the other table.
The different types of relationships in DBMS are as follows:
This is a process of managing simultaneous operations in a database so that database integrity is not compromised. The following are the two approaches involved in concurrency control:
ACID stands for Atomicity, Consistency, Isolation, Durability. It is used to ensure that the data transactions are processed reliably in a database system.
The process of organizing data to avoid any duplication of data and redundancy is known as Normalization. There are many successive levels of normalization which are known as normal forms. Each consecutive normal form depends on the previous one. The following are the first three normal forms. Apart from these, you have higher normal forms such as BCNF.
There are mainly 7 types of Keys, that can be considered in a database. I am going to consider the below tables to explain to you the various keys.
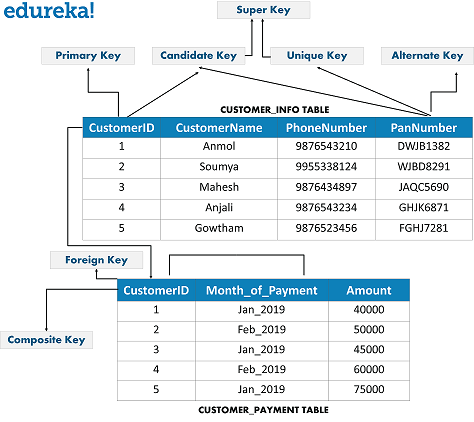
Fig 1: Different Types of Keys in Database – DBMS Interview Questions
A correlated subquery is also a sort of subquery reliant on another query. So, when subqueries are executed for each of the rows of outer queries, then they are termed as correlated subqueries. Each subquery is executed a single time for every row of the outer query.
You can also understand correlated subqueries as those queries, which are used for row-by-row processing by the parent statement. Here, the parent statement can be SELECT, UPDATE or DELETE statement.
Data partitioning is the process of dividing a logical database into independent units for the betterment of availability, performance, and manageability.
The importance of database partitioning is as follows:
Functional Dependency: A functional dependency is a constraint that is used in describing the relationship among different attributes in a relation.
Example: Consider a relation “A1” having attributes X and Y. The functional dependency among these two attributes will be X -> Y, this implies that Y is functionally dependent on X.
Transitive Dependency: A transitive dependency is a constraint that can only occur in a relation of three or more attributes.
Example: Consider a relation “A1” having attributes X, Y and Z. Now, X->Z is said to hold transitive dependency, only if the following functional dependencies holds true:
| Two-tier architecture | Three-tier architecture |
| This is similar to the client-server architecture. | This architecture contains an extra layer between the client and the server. |
| Clients directly communicate with the database at the server-side | Clients communicate with an application(GUI) on the server-side, that makes the system more secure and accessible. This application thereafter communicates with the database system. |

Fig 2: Two-Tier vs Three-Tier Architecture – DBMS Interview Questions
| Unique Key | Primary Key |
| Unique Key can have a NULL value | The primary key cannot have a NULL value |
| Each table can have more than one unique key | Each table can have only one primary key |
A checkpoint is a mechanism where all the previous logs are removed from the system and are permanently stored on the storage disk. So, basically, checkpoints are those points from where the transaction log record can be used to recover all the committed data up to the point of crash.
Next, le us discuss one of the most commonly asked DBMS interview questions, that is:
| Triggers | Stored Procedures |
| A special kind of stored procedure that is not called directly by a user. In fact, a trigger is created and is programmed to fire when a specific event occurs. | A group of SQL statements which can be reused again and again. These statements are created and stored in the database. |
| A trigger cannot be called or execute directly by a user. Only when the corresponding events are fired, triggers are created. | Can execute stored procedures by using the exec command, whenever we want. |
| You cannot schedule a trigger. | You can schedule a job to execute the stored procedure on a pre-defined time. |
| Cannot directly call another trigger within a trigger. | Call a stored procedure from another stored procedure. |
| Parameters cannot be passed as input | Parameters can be passed as input |
| Cannot return values. | Can return zero or n values. |
| Transactions are not allowed within a trigger. | You can use transactions within a stored procedure. |
| Hash join | Merge join | Nested loops |
| The hash join is used when you have to join large tables. | Merge join is used when projections of the joined tables are sorted on the join columns. | The nested loop consists of an outer loop and an inner loop. |
Indexes are data structures responsible for improving the speed of data retrieval operations on a table. This data structure uses more storage space to maintain extra copies of data by using additional writes. So, indexes are mainly used for searching algorithms, where you wish to retrieve data in a quick manner.
The differences between clustered and non-clustered index are as follows:
| Clustered Index | Non-clustered Index |
| A clustered index is faster | Non clustered index is relatively slower |
| Alters the way records are stored in a database as it sorts out rows by the column which is set to be clustered index | Does not alter the way it was stored but it creates a separate object within a table which points back to the original table rows after searching |
| One table can only have one clustered index | One table can only have many non clustered indexes |
Intension: Intension or most commonly known as Database schema defines the description of the database. This is specified during the database design and mostly remains unchanged.
Extension: Extension is the number of tuples available in the database at any instance of time. This value keeps changing as and when the tuples are created, updated and destroyed. So, the data present in the database at a specific instance of time is known as the extension of the database or most commonly known as the snapshot of the database.
A cursor is a database object which helps in manipulating data, row by row and represents a result set.
The types of cursor are as follows:
When you say an application has data independence, it implies that the application is independent of the storage structure and data access strategies of data.
The different integrity rules present in DBMS are as follows:
Fill Factor is used to mention the percentage of space left on every leaf-level page, which is packed with data. Usually, the default value is 100.
The process of boosting a collection of indexes is known as Index hunting. This is done as indexes improve the query performance and the speed at which they are processed.
It helps in improving query performance in the following way:
| Network Database Model | Hierarchical Database Model |
| Each parent node can have multiple children nodes and vice versa. | A top-down structure where each parent node can have many child nodes. But, a child node can have only a single parent node. |
| Supports one-to-one, one-to-many, and many-to-many relationships | Supports one-tone and one-to-many relationships |
Deadlock is a situation which occurs when two transactions wait on a resource which is locked or other transaction holds. Deadlocks can be prevented by making all the transactions acquire all the locks at the same instance of time. So, once deadlock occurs, the only way to cure is to abort one of the transactions and remove the partially completed work.
| Exclusive Lock | Shared Lock |
| An exclusive lock is a lock on a data item when a transaction is about to perform the write operation. | A shared lock allows more than one transaction to read the data items. |
Next, in this article on DBMS interview questions, let us discuss the top questions asked about SQL. Donwload and Install SQL Server here
| DROP | TRUNCATE | DELETE |
| Used to delete a database, table or a view | Used to delete all rows from a table | Used to delete a row in the table |
| Data cannot be rollbacked | Data cannot be rollbacked | Data can be rollbacked |
| A DDL command | A DDL command | A DML command. |
| Slower than TRUNCATE | Faster than DROP and DELETE | Slower than TRUNCATE |
| Deletes the full structure of the table | Preserves the structure of the table | Deletes the structure of the row from a table |
SQL aka Structured Query Language is the core of the relational database which is used for accessing and managing the databases. This language is used to manipulate and retrieve data from a structured data format in the form of tables and holds relationships between those tables. So, in layman terms, you can use SQL to communicate with the database.
A subquery is a query inside another query where a query is defined to retrieve data or information back from the database. In a subquery, the outer query is called as the main query whereas the inner query is called subquery. Subqueries are always executed first and the result of the subquery is passed on to the main query. It can be nested inside a SELECT, UPDATE or any other query. A subquery can also use any comparison operators such as >,< or =.
| UNION | UNION ALL |
| Combines the result of two or more SELECT statements consisting of distinct values | Combines the result set of two or more SELECT statements consisting of duplicate values |
| Syntax: UNION | Syntax: UNION ALL |
| Has low performance than UNION ALL, as duplicate rows need to be removed. | Has better performance than UNION, as duplicate rows need not have to be removed. |
CLAUSE in SQL is used to limit the result set by mentioning a condition to the query. So, you can use a CLAUSE to filter rows from the entire set of records.
Example: WHERE HAVING clause.
| HAVING | WHERE |
| Used only with SELECT statement | Used in a GROUP BY clause |
| Used with the GROUP BY function in a query | Applied to each row before they are a part of the GROUP BY function in a query |
Note: Whenever GROUP BY is not used, HAVING behaves like a WHERE clause.
You can perform pattern matching in SQL by using the LIKE operator. With the LIKE operator, you can use the following symbols:
%(Percentage sign) – To match zero or more characters.
_ (Underscore) –To match exactly one character.
Example:
SELECT * FROM Customers WHERE CustomerName LIKE ‘s%’
SELECT * FROM Customers WHERE CustomerName like ‘xyz_’
There are three case manipulation functions in SQL, namely:
LOWER: This function returns the string in lowercase. It takes a string as an argument and returns it by converting it into lower case.
Syntax: LOWER(‘string’)
UPPER: This function returns the string in uppercase. It takes a string as an argument and returns it by converting it into uppercase.
Syntax: UPPER(‘string’)INITCAP: This function returns the string with the first letter in uppercase and the rest of the letters in lowercase.
Syntax: INITCAP(‘string’)
A JOIN clause is used to combine rows from two or more tables, based on a related column between them. It is used to merge two tables or retrieve data from there. There are 4 joins in SQL namely:
A view in SQL is a single table, which is derived from other tables. So, a view contains rows and columns similar to a real table and has fields from one or more table.
To create a view, use the following syntax:
CREATE VIEW ViewName AS SELECT Column1, Column2, ..., ColumnN FROM TableName WHERE Condition;
To update a view, use the following syntax:
CREATE VIEW OR REPLACE ViewName AS SELECT Column1, Column2, ..., ColumnN FROM TableName WHERE Condition;
To drop a view, use the following syntax:
DROP VIEW ViewName;
Next, in this article on DBMS interview questions, let us discuss the most frequently asked queries about SQL.
Consider you have a table named Customers, having details such as CustomerID, CustomerName and so on. Now, if you want to create a duplicate table named ‘DuplicateCustomer’ with the data present in it, you can mention the following query:
CREATE TABLE DuplicateCustomer AS SELECT * FROM Customers;
Similarly, if you want to create a duplicate table without the data present, mention the following query:
CREATE TABLE DuplicateCustomer AS SELECT * FROM Customers WHERE 1=2;
To write a query to calculate the even and odd records from a table, you can write two different queries by using the MOD function.
So, if you want to retrieve the even records from a table, you can write a query as follows:
SELECT CustomerID FROM (SELECT rowno, CustomerID from Customers) where mod(rowno,2)=0;
Similarly, if you want to retrieve the odd records from a table, you can write a query as follows:
SELECT CustomerID FROM (SELECT rowno, CustomerID from Customers) where mod(rowno,2)=1;
To remove duplicate rows from a table, you have to initially select the duplicate rows from the table without using the DISTINCT keyword. So, to select the duplicate rows from the table, you can write a query as follows:
SELECT CustomerNumber FROM Customers WHERE ROWID (SELECT MAX (rowid) FROM Customers C WHERE CustomerNumber = C.CustomerNumber);
Now, to delete the duplicate records from the Customers table, mention the following query:
DELETE FROM Customers WHERE ROWID(SELECT MAX (rowid) FROM Customers C WHERE CustomerNumber = C.CustomerNumber);
Well, there are multiple ways to add email validation to your database, but one out the lot is as follows:
SELECT Email FROM Customers WHERE NOT REGEXP_LIKE(Email, &lsquo;[A-Z0-9._%+-]+@[A-Z0-9.-]+.[A-Z]{2,4}&rsquo;, &lsquo;i&rsquo;);
To write a query to retrieve the last day of the next month in Oracle, you can write a query as follows:
SELECT LAST_DAY (ADD_MONTHS (SYSDATE,1)) from dual;
So this brings us to the end of the DBMS Interview Questions article. I hope this set of DBMS Interview Questions will help you ace your job interview. All the best for your interview!
Check out this MySQL DBA Certification Training by Edureka, a trusted online learning company with a network of more than 250,000 satisfied learners spread across the globe. This course trains you on the core concepts & advanced tools and techniques to manage data and administer the MySQL Database. It includes hands-on learning on concepts like MySQL Workbench, MySQL Server, Data Modeling, MySQL Connector, Database Design, MySQL Command line, MySQL Functions, etc. End of the training you will be able to create and administer your own MySQL Database and manage data.
Got a question for us? Please mention it in the comments section of this “DBMS Interview Questions” article and we will get back to you as soon as possible.



















 REGISTER FOR FREE WEBINAR
REGISTER FOR FREE WEBINAR  Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP







Thanks a lot for preparing this.