






Data Science and Machine Learning Internship ...
- 1k Enrolled Learners
- Weekend/Weekday
- Live Class
(50)
Web Scraping with Python
Imagine you have to pull a large amount of data from websites and you want to do it as quickly as possible. How would you do it without manually going to each website and getting the data? Well, “Web Scraping” is the answer. Web Scraping just makes this job easier and faster.
This Edureka Python Full Course helps you to became a master in basic and advanced Python Programming Concepts.
In this article on Web Scraping with Python, you will learn about web scraping in brief and see how to extract data from a website with a demonstration. I will be covering the following topics:
Web scraping is used to collect large information from websites. But why does someone have to collect such large data from websites? To know about this, let’s look at the applications of web scraping:
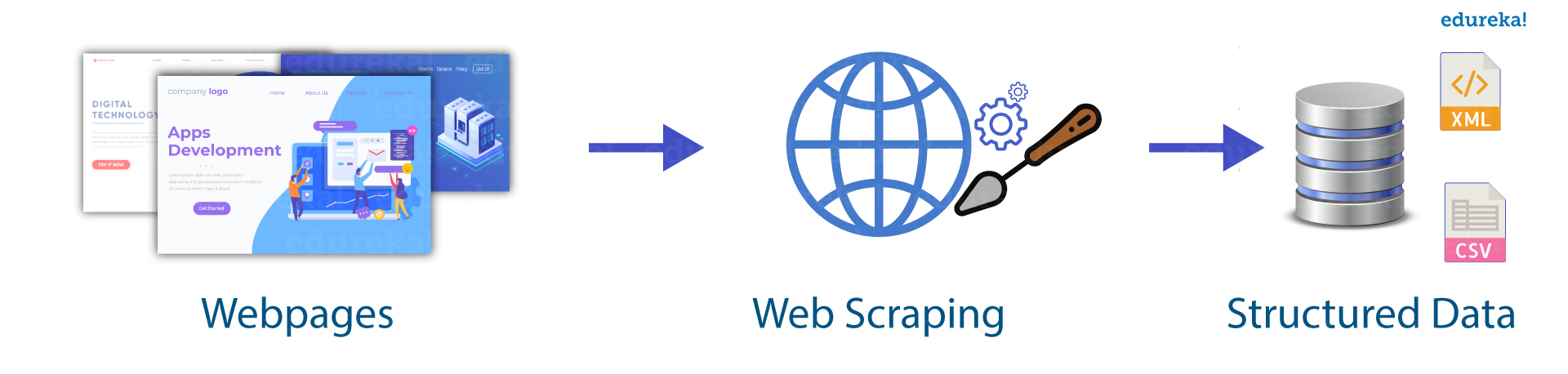
Web scraping is an automated method used to extract large amounts of data from websites. The data on the websites are unstructured. Web scraping helps collect these unstructured data and store it in a structured form. There are different ways to scrape websites such as online Services, APIs or writing your own code. In this article, we’ll see how to implement web scraping with python.
Talking about whether web scraping is legal or not, some websites allow web scraping and some don’t. To know whether a website allows web scraping or not, you can look at the website’s “robots.txt” file. You can find this file by appending “/robots.txt” to the URL that you want to scrape. For this example, I am scraping Flipkart website. So, to see the “robots.txt” file, the URL is www.flipkart.com/robots.txt.
Here is the list of features of Python which makes it more suitable for web scraping.
Find out our Python Training in Top Cities/Countries
| India | USA | Other Cities/Countries |
| Bangalore | New York | UK |
| Hyderabad | Chicago | London |
| Delhi | Atlanta | Canada |
| Chennai | Houston | Toronto |
| Mumbai | Los Angeles | Australia |
| Pune | Boston | UAE |
| Kolkata | Miami | Dubai |
| Ahmedabad | San Francisco | Philippines |
When you run the code for web scraping, a request is sent to the URL that you have mentioned. As a response to the request, the server sends the data and allows you to read the HTML or XML page. The code then, parses the HTML or XML page, finds the data and extracts it.
To extract data using web scraping with python, you need to follow these basic steps:
Now let us see how to extract data from the Flipkart website using Python.
Learn Python, Deep Learning, NLP, Artificial Intelligence, Machine Learning with these AI and ML courses a PG Diploma certification program by NIT Warangal.
As we know, Python is has various applications and there are different libraries for different purposes. In our further demonstration, we will be using the following libraries:
Subscribe to our YouTube channel to get new updates..!
Pre-requisites:
Let’s get started!
For this example, we are going scrape Flipkart website to extract the Price, Name, and Rating of Laptops. The URL for this page is https://www.flipkart.com/laptops/~buyback-guarantee-on-laptops-/pr?sid=6bo%2Cb5g&uniqBStoreParam1=val1&wid=11.productCard.PMU_V2.
Step 2: Inspecting the Page
The data is usually nested in tags. So, we inspect the page to see, under which tag the data we want to scrape is nested. To inspect the page, just right click on the element and click on “Inspect”.
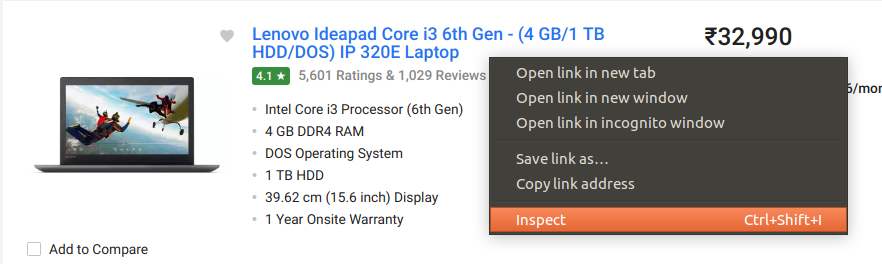
When you click on the “Inspect” tab, you will see a “Browser Inspector Box” open.
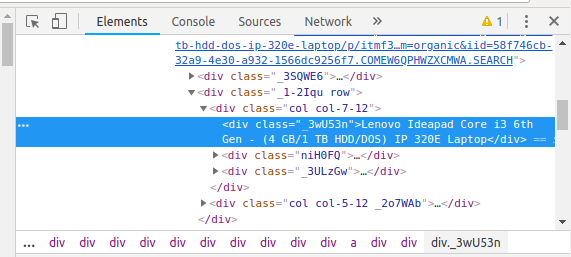
Let’s extract the Price, Name, and Rating which is in the “div” tag respectively.
First, let’s create a Python file. To do this, open the terminal in Ubuntu and type gedit <your file name> with .py extension.
I am going to name my file “web-s”. Here’s the command:
gedit web-s.py
Now, let’s write our code in this file.
First, let us import all the necessary libraries:
from selenium import webdriver from BeautifulSoup import BeautifulSoup import pandas as pd
To configure webdriver to use Chrome browser, we have to set the path to chromedriver
driver = webdriver.Chrome("/usr/lib/chromium-browser/chromedriver")Refer the below code to open the URL:
products=[] #List to store name of the product
prices=[] #List to store price of the product
ratings=[] #List to store rating of the product
driver.get("https://www.flipkart.com/laptops/~buyback-guarantee-on-laptops-/pr?sid=6bo%2Cb5g&amp;amp;amp;amp;amp;amp;amp;amp;amp;uniq")
Now that we have written the code to open the URL, it’s time to extract the data from the website. As mentioned earlier, the data we want to extract is nested in <div> tags. So, I will find the div tags with those respective class-names, extract the data and store the data in a variable. Refer the code below:
content = driver.page_source
soup = BeautifulSoup(content)
for a in soup.findAll('a',href=True, attrs={'class':'_31qSD5'}):
name=a.find('div', attrs={'class':'_3wU53n'})
price=a.find('div', attrs={'class':'_1vC4OE _2rQ-NK'})
rating=a.find('div', attrs={'class':'hGSR34 _2beYZw'})
products.append(name.text)
prices.append(price.text)
ratings.append(rating.text)
To run the code, use the below command:
python web-s.py
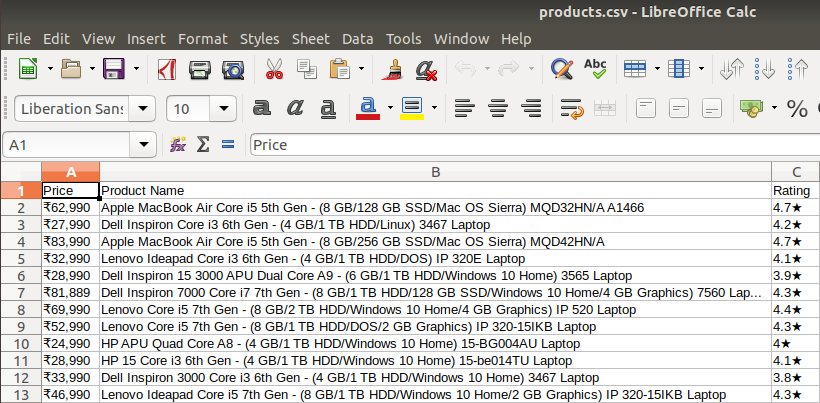
After extracting the data, you might want to store it in a format. This format varies depending on your requirement. For this example, we will store the extracted data in a CSV (Comma Separated Value) format. To do this, I will add the following lines to my code:
df = pd.DataFrame({'Product Name':products,'Price':prices,'Rating':ratings})
df.to_csv('products.csv', index=False, encoding='utf-8')Now, I’ll run the whole code again.
A file name “products.csv” is created and this file contains the extracted data.
I hope you guys enjoyed this article on “Web Scraping with Python”. I hope this blog was informative and has added value to your knowledge. Now go ahead and try Web Scraping. Experiment with different modules and applications of Python.
If you wish to know about Web Scraping With Python on Windows platform, then the below video will help you understand how to do it or you can also join our Python Master course.
Got a question regarding “web scraping with Python”? You can ask it on edureka! Forum and we will get back to you at the earliest or you can join our Python Training in Hobart today..
To get in-depth knowledge on Python Programming language along with its various applications, you can enroll here for live online Python training with 24/7 support and lifetime access.
| Course Name | Date | |
|---|---|---|
| Python Certification Training Course | Class Starts on 28th January,2023 28th January SAT&SUN (Weekend Batch) | View Details |
| Python Certification Training Course | Class Starts on 25th February,2023 25th February SAT&SUN (Weekend Batch) | View Details |
| Python Certification Training Course | Class Starts on 25th March,2023 25th March SAT&SUN (Weekend Batch) | View Details |






































 REGISTER FOR FREE WEBINAR
REGISTER FOR FREE WEBINAR  Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP










thanks for a great article on web scraping,it was helpful
Hello! great article about web scraping service.
Wonderful! It works perfectly….
syntax error when trying to run the redditbot with crawl, can you help?
Blog was helpful! Thank you so much Omkar bhai?!!
Hey Brunda, we are glad you found the blog helpful! Do take a look at our other blogs too and please do consider subscribing. Cheers!
Really very informative. Easy to understand… Good going Omkar..
Hey Markandeshwar, we are glad you loved the blog. Do check it our other blogs and please do consider subscribing. Cheers!