






Azure Data Engineer Associate Certification C ...
- 2k Enrolled Learners
- Weekend
- Live Class
(550)
Pig is an open-source high level data flow system. It provides a simple language called Pig Latin, for queries and data manipulation, which are then compiled in to MapReduce jobs that run on Hadoop.
Pig is important as companies like Yahoo, Google and Microsoft are collecting huge amounts of data sets in the form of click streams, search logs and web crawls. Pig is also used in some form of ad-hoc processing and analysis of all the information.
Pig was originally developed by Yahoo in 2006, for researchers to have an ad-hoc way of creating and executing MapReduce jobs on very large data sets. It was created to reduce the development time through its multi-query approach. Pig is also created for professionals from non-Java background, to make their job easier. You can even check out the details of Big Data with the Data Engineer Course.
Pig can be used under following scenarios:
Yahoo uses Pig for the following purpose:
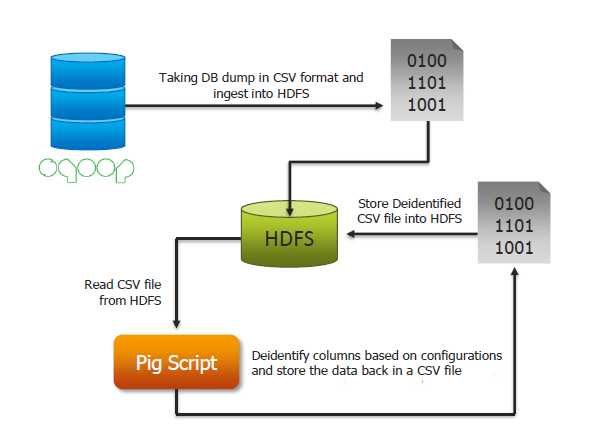 The above diagram gives a clear, step by step explanation of how the data flows through Sqoop, HDFS and Pig script.
The above diagram gives a clear, step by step explanation of how the data flows through Sqoop, HDFS and Pig script.

Source: ftp://ftp.ncdc.noaa.gov/pub/data/uscrn/products/daily01/

Here’s the hierarchy of Pig’s program structure:

Pig Latin program is made up of a series of operations or transformations that are applied to the input data to produce output. The job of Pig is to convert the transformations in to a series of MapReduce jobs. You can get a better understanding with the Azure Data Engineering Certification in Washington.
Pig comprises of 4 basic types of data models. They are as follows:

Got a question for us? Mention them in the comments section and we will get back to you.
Related Posts:
Apache Pig UDF – Eval, Aggregate & Filter Functions
| Course Name | Date | |
|---|---|---|
| Big Data Hadoop Certification Training Course | Class Starts on 11th February,2023 11th February SAT&SUN (Weekend Batch) | View Details |
| Big Data Hadoop Certification Training Course | Class Starts on 8th April,2023 8th April SAT&SUN (Weekend Batch) | View Details |





































 REGISTER FOR FREE WEBINAR
REGISTER FOR FREE WEBINAR  Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP










Hi….
pig -version
Exception in thread “main” java.lang.NoClassDefFoundError: jline/ConsoleReaderInputStream
at java.base/java.lang.Class.forName0(Native Method)
at java.base/java.lang.Class.forName(Class.java:398)
at org.apache.hadoop.util.RunJar.run(RunJar.java:214)
at org.apache.hadoop.util.RunJar.main(RunJar.java:136)
Caused by: java.lang.ClassNotFoundException: jline.ConsoleReaderInputStream
at java.base/java.net.URLClassLoader.findClass(URLClassLoader.java:471)
at java.base/java.lang.ClassLoader.loadClass(ClassLoader.java:588)
at java.base/java.lang.ClassLoader.loadClass(ClassLoader.java:521)
… 4 more
How to resolve the above error…..
Hi,
I am a learner of hadoop. i dont know java. I have linux knowledge.
could you please explain about the UDF,UDAF,UDTF in hive & Pig.
can you please explain step by step.
Thanks,
Anbu k.
Hi Anbu, they help
us to write a user defined functions on our own and then use them in
Pig/Hive.
To know more about them please refer to the following links.
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF
http://pig.apache.org/docs/r0.11.0/udf.html#udf-java“