







Azure Data Engineer Associate Certification C ...
- 2k Enrolled Learners
- Weekend
- Live Class
(550)
Machine learning has gone through many recent developments and is becoming more popular day by day. Machine Learning is being used in various projects to find hidden information in data by people from all domains, including Computer Science, Mathematics, and Management. It was just a matter of time that Apache Spark Jumped into the game of Machine Learning with Python, using its MLlib library. It has also been noted that this combination of Python and Apache Spark is being preferred by many over Scala for Spark and this has led to PySpark Certification becoming a widely engrossed skill in the market today. So, in this PySpark MLlib Tutorial, I’ll be discussing the following topics:
Machine learning is a method of Data Analysis that automates Analytical Model building. Using algorithms that iteratively learn from data, machine learning allows computers to find hidden insights without being explicitly programmed where to look. It focuses on the development of computer programs that can teach themselves to grow and change when exposed to new data. Machine Learning uses the data to detect patterns in a dataset and adjust program actions accordingly.
Most industries working with large amounts of data have recognized the value of machine learning technology. By gleaning insights from this data, often in real time, organizations are able to work more efficiently or gain an advantage over competitors. To know more about Machine Learning and it’s various types you can refer to this What is Machine Learning? Blog.
Now that you have got a brief idea of what is Machine Learning, Let’s move forward with this PySpark MLlib Tutorial Blog and understand what is MLlib and what are its features?
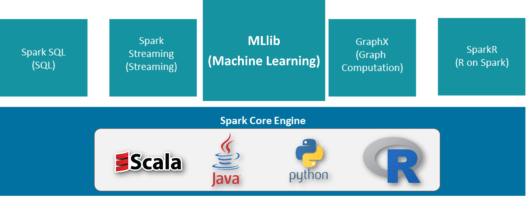
PySpark MLlib is a machine-learning library. It is a wrapper over PySpark Core to do data analysis using machine-learning algorithms. It works on distributed systems and is scalable. We can find implementations of classification, clustering, linear regression, and other machine-learning algorithms in PySpark MLlib.
This video will provide you with a detailed and comprehensive knowledge of PySpark MLlib.
Machine learning algorithms, applications, and platforms are helping manufacturers find new business models, fine-tune product quality, and optimize manufacturing operations to the shop floor level. So Let’s continue our PySpark MLlib Tutorial and understand how the various industries are using Machine Learning.

Government:
Government agencies such as public safety and utilities have a particular need for machine learning. They use it for face detection, security and fraud detection. Public sector agencies are making use of machine learning for government initiatives to gain vital insights into policy data.
Marketing and E-commerce:
The number of purchases made online is steadily increasing, which allows companies to gather detailed data on the whole customer experience. Websites recommending items you might like based on previous purchases are using machine learning to analyze your buying history and promote other items you’d be interested in.
Transportation:
Analyzing data to identify patterns and trends is key to the transportation industry, which relies on making routes more efficient and predicting potential problems to increase profitability. Companies use ML to enable an efficient ride-sharing marketplace, identify suspicious or fraudulent accounts, suggest optimal pickup and drop-off points.

Finance:
Today, machine learning has come to play an integral role in many phases of the financial ecosystem, from approving loans to managing assets, to assessing risks. Banks and other businesses in the financial industry use machine learning technology to prevent fraud.

Healthcare:
Machine learning is a fast-growing trend in the healthcare industry, thanks to the advent of wearable devices and sensors that can use data to assess a patient’s health in real time. Google has developed a machine learning algorithm to help identify cancerous tumors on mammograms. Stanford is using a deep learning algorithm to identify skin cancer.
Now that you have an idea of what is Machine Learning and what are the various areas in the industry where it is used, let’s continue our PySpark MLlib Tutorial and understand what a typical Machine Learning Lifecycle looks like.
Subscribe to our youtube channel to get new updates..!
A typical Machine Learning Cycle involves majorly two phases:
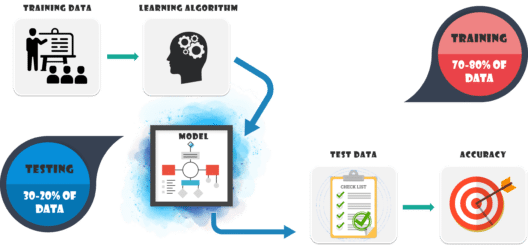
In Machine Learning, we basically try to create a model to predict on the test data. So, we use the training data to fit the model and testing data to test it. The models generated are to predict the results unknown which is named as the test set. As you pointed out, the dataset is divided into train and test set in order to check accuracies, precisions by training and testing it on it.
Now that you have an idea of what a Typical Machine Learning Lifecycle works, let’s move forward with our PySpark MLlib Tutorial blog with MLlib features and the various languages supported by it.
We know that PySpark is good for iterative algorithms. Using iterative algorithms, many machine-learning algorithms have been implemented in PySpark MLlib. Apart from PySpark efficiency and scalability, PySpark MLlib APIs are very user-friendly.
A company system was hacked and lots of data were stolen. Fortunately, metadata for each session hackers used to connect was recorded and is available to us. There are 3 potential hackers, or even more.
A common practice among hackers is the tradeoff of the job. This means that hackers do roughly the same amount of hacks. So here we are going to use clustering to find out the number of hackers.
Firstly we need to initialize spark session.
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('find_hacker').getOrCreate()
We will be using Kmeans Algorithm to do our analysis and for that, we need to import the Kmeans Library and then we’ll load our dataset with spark.read method.
from pyspark.ml.clustering import KMeans
dataset = spark.read.csv("file:///home/edureka/Downloads/hack_data.csv",header=True,inferSchema=True)
Let’s have a look at the schema of data to get a better understanding of what we are dealing with.
dataset.printSchema()

We must transform our data using the VectorAssembler function to a single column where each row of the DataFrame contains a feature vector. In order to create our clusters, we need to select columns based on which we will then create our features column. Here we are using the columns:
from pyspark.ml.linalg import Vectors from pyspark.ml.feature import VectorAssembler feat_cols = ['Session_Connection_Time', 'Bytes Transferred', 'Kali_Trace_Used', 'Servers_Corrupted', 'Pages_Corrupted','WPM_Typing_Speed'] vec_assembler = VectorAssembler(inputCols = feat_cols, outputCol='features') final_data = vec_assembler.transform(dataset)
Centering and Scaling happen independently on each feature by computing the relevant statistics on the samples in the training set. Mean and standard deviation are then stored to be used on later data using the transform method.
Standardization of a dataset is a common requirement for many machine learning estimators: they might behave badly if the individual feature does not more or less look like standard normally distributed data.
from pyspark.ml.feature import StandardScaler scaler = StandardScaler(inputCol="features", outputCol="scaledFeatures", withStd=True, withMean=False)
Let’s Compute summary statistics by fitting the StandardScaler. Then Normalize each feature to have a unit standard deviation.
scalerModel = scaler.fit(final_data) cluster_final_data = scalerModel.transform(final_data) kmeans3 = KMeans(featuresCol='scaledFeatures',k=3) kmeans2 = KMeans(featuresCol='scaledFeatures',k=2)
We have to first build our Model. The number of desired clusters is then passed to the algorithm. We then compute Within Set Sum of Squared Error (WSSSE). We use the values derived from these to figure out whether we have 2 or 3 hackers.
model_k3 = kmeans3.fit(cluster_final_data)
model_k2 = kmeans2.fit(cluster_final_data)
 
wssse_k3 = model_k3.computeCost(cluster_final_data)
wssse_k2 = model_k2.computeCost(cluster_final_data)
print("With K=3")
print("Within Set Sum of Squared Errors = " + str(wssse_k3))
print('--'*30)
print("With K=2")
print("Within Set Sum of Squared Errors = " + str(wssse_k2))

We’ll check the values of WSSSE for 2 to 8 and see if we have an elbow in the list.
for k in range(2,9):
kmeans = KMeans(featuresCol='scaledFeatures',k=k)
model = kmeans.fit(cluster_final_data)
wssse = model.computeCost(cluster_final_data)
print("With K={}".format(k))
print("Within Set Sum of Squared Errors = " + str(wssse))
print('--'*30)

Here we can see that the value of WSSSE is continuously decreasing and we don’t have an elbow. So most probably the value of K is 2 and not 3. Let’s continue this PySpark MLlib Tutorial and get to the verdict.
Let’s find out how many hackers were involved based on the number of hacks done.
model_k3.transform(cluster_final_data).groupBy('prediction').count().show()
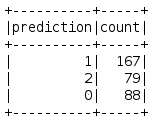
model_k2.transform(cluster_final_data).groupBy('prediction').count().show()

So, here we can see that for 3 hackers, our model has produced 167,79 and 88 hacks. This is not possible as the hackers usually divide the tasks in between them. In our model where K =2, we get 167 number of hacks for both the hackers. Hence there were only 2 hackers involved.
Let’s continue our PySpark MLlib Tutorial blog and solve another problem faced by many companies ie. Customer Churn.
Churn prediction is big business. It minimizes customer defection by predicting which customers are likely to cancel a subscription to a service. Though originally used within the telecommunications industry, it has become common practice across banks, ISPs, insurance firms, and other verticals.
The prediction process is heavily data-driven and often utilizes advanced machine learning techniques. Here, we’ll take a look at what types of customer data are typically used, do some preliminary analysis of the data, and generate churn prediction models – all with PySpark and its machine learning frameworks.

A marketing agency has many customers that use their service to produce ads for the client/customer websites. They’ve noticed that they have quite a bit of churn in clients. They basically randomly assign account managers right now but want you to create a machine learning model that will help predict which customers will churn (stop buying their service) so that they can correctly assign the customers most at risk to churn an account manager. Luckily they have some historical data.
So, can you help them out?
Let’s load up the required libraries. Here we are going to use Logistic Regression.
from pyspark.ml.classification import LogisticRegression
Let’s load up the training data and the testing data (incoming data for testing purposes)
input_data=spark.read.csv('file:///home/edureka/Downloads/customer_churn.csv',header=True,inferSchema=True)
test_data=spark.read.csv('file:///home/edureka/Downloads/new_customers.csv',header=True,inferSchema=True)
We are going to have a look at the schema of data to get a better understanding of what we are dealing with.
input_data.printSchema() //training data

Here we have column Churn. Let’s see the schema of the testing data as well.
test_data.printSchema() //testing data

from pyspark.ml.linalg import Vectors from pyspark.ml.feature import VectorAssembler assembler=VectorAssembler(inputCols=['Age','Total_Purchase','Account_Manager','Years','Num_Sites'],outputCol='features') output_data=assembler.transform(input_data)
Let’s have a look at the schema of the output data.
output_data.printSchema()

As you guys can see, we have a features column here, based on which the Classification will occur.
final_data=output_data.select('features','churn') //creating final data with only 2 columns
train,test=final_data.randomSplit([0.7,0.3]) //splitting data
model=LogisticRegression(labelCol='churn') //creating model
model=model.fit(train) //fitting model on training dataset
summary=model.summary
summary.predictions.describe().show() //summary of the predictions on training data

The evaluation of binary classifiers compares two methods of assigning a binary attribute, one of which is usually a standard method and the other is being investigated. There are many metrics that can be used to measure the performance of a classifier or predictor; different fields have different preferences for specific metrics due to different goals.
from pyspark.ml.evaluation import BinaryClassificationEvaluator predictions=model.evaluate(test)
Next, we’ll create an evaluator and use the Binary Classification Evaluator to predict the churn.
evaluator=BinaryClassificationEvaluator(rawPredictionCol='prediction',labelCol='churn') evaluator.evaluate(predictions.predictions) model1=LogisticRegression(labelCol='churn') model1=model1.fit(final_data) test_data=assembler.transform(test_data)
Now we are going to use the model to evaluate the new data
results=model1.transform(test_data)
results.select('Company','prediction').show()

So here we can see the potential client that can leave the organization and with this analysis, we come to the end of this PySpark MLlib Tutorial Blog.
I hope you enjoyed this PySpark MLlib Tutorial blog. If you are reading this, Congratulations! You are no longer a newbie to PySpark MLlib. Try out these simple example on your systems now.
Now that you have understood basics of PySpark MLlib Tutorial, check out the Pyspark Training by Edureka, a trusted online learning company with a network of more than 250,000 satisfied learners spread across the globe. Edureka’s Python Spark Certification Training using PySpark is designed to provide you with the knowledge and skills that are required to become a successful Spark Developer using Python and prepare you for the Cloudera Hadoop and Spark Developer Certification Exam (CCA175).
Got a question for us? Please mention it in the comments section and we will get back to you.
| Course Name | Date | |
|---|---|---|
| PySpark Certification Training Course | Class Starts on 4th March,2023 4th March SAT&SUN (Weekend Batch) | View Details |






































 REGISTER FOR FREE WEBINAR
REGISTER FOR FREE WEBINAR  Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP










Your tutorials are good. Please upload the data sets also. It will be really awesome. Thanks a lot