






Azure Data Engineer Associate Certification C ...
- 2k Enrolled Learners
- Weekend
- Live Class
(550)
Contributed by Prithviraj Bose
Broadcast variables are useful when large datasets needs to be cached in executors. This blog explains how to get started.
What are Broadcast Variables?
Broadcast variables in Apache Spark is a mechanism for sharing variables across executors that are meant to be read-only. Without broadcast variables these variables would be shipped to each executor for every transformation and action, and this can cause network overhead. However, with broadcast variables, they are shipped once to all executors and are cached for future reference.
Imagine that while doing a transformation we need to lookup a large table of zip codes/pin codes. Here, it is neither feasible to send the large lookup table every time to the executors, nor can we query the database every time. The solution should be to convert this lookup table to a broadcast variables and Spark will cache it in every executor for future reference.
Let’s take a simple example to understand the above concepts. We have a CSV file with names of countries and their capitals. The CSV file can be found here.

Assuming we are processing demographic data of countries and we need to get the capital of that country. In this case we can convert the data in the CSV file to a broadcast variable.
First we load the CSV file in a map, if the file is found then the method returns Some(countries) else it returnsNone.
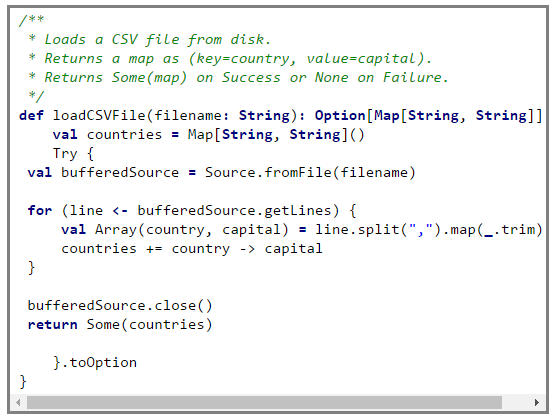
After successful loading of the CSV file we convert the map to a broadcast variable and use it in our programme.
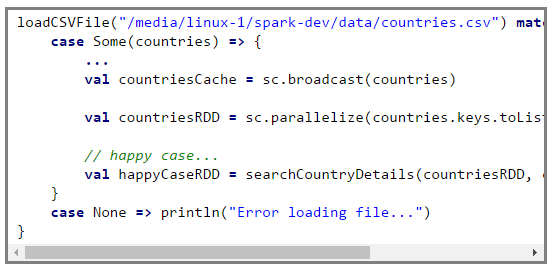
In the code snippet above we load the CSV file to a mapcountries then we convert that map to a broadcast variablecountriesCache. Subsequently, we create an RDD from the keys of countries. In the searchCountryDetails method we search for all the countries starting with a user defined letter and the method returns an RDD of countries along with their capitals. The broadcast variable countrieCache is used for looking up the capitals.
This way we need not send the whole CSV data every time we need to search.
The code for the searchCountryDetails is shown below,
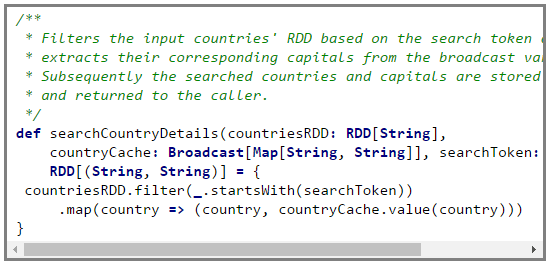
The whole source code can be found here.
Got a question for us? Mention them in the comment section and we will get back to you.
Related Posts:
| Course Name | Date | |
|---|---|---|
| Apache Spark and Scala Certification Training Course | Class Starts on 11th February,2023 11th February SAT&SUN (Weekend Batch) | View Details |
| Apache Spark and Scala Certification Training Course | Class Starts on 8th April,2023 8th April SAT&SUN (Weekend Batch) | View Details |





































 REGISTER FOR FREE WEBINAR
REGISTER FOR FREE WEBINAR  Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP









