






AWS Solutions Architect Certification Trainin ...
- 141k Enrolled Learners
- Weekend/Weekday
- Live Class
(56150)
AWS has been rated a Leader in the 2022 Magic Quadrant for Cloud Infrastructure and Platform Services for the twelfth time in a row (CIPS). AWS is the longest-running CIPS Magic Quadrant Leader, according to Gartner. 48% of enterprises plan to keep spending steadily on cloud, according to IDC research. Undoubtedly, the AWS Solution Architect position is one of the most sought after amongst IT jobs. You, too, can maximize the Cloud computing career opportunities that are sure to come your way by taking AWS Certification training with Edureka. In this blog, we are here to set you up for your next interview with AWS Interview Questions and Answers
Why AWS Interview Questions?
The AWS Solution Architect Role: With regards to AWS, a Solution Architect would design and define AWS architecture for existing systems, migrating them to cloud architectures as well as developing technical road-maps for future AWS cloud implementations. So, through this AWS interview questions and answers article, I will bring you top and frequently asked AWS interview questions. Gain proficiency in designing, planning, and scaling cloud implementation with the AWS Masters Program.
The following is the outline of this article:
Now in every section, we will start with AWS basic interview questions, and then move towards AWS interview questions and answers for experienced people which are more technically challenging,
For a detailed discussion on this topic, please refer our Cloud Computing blog. Following is the comparison between two of the most popular Cloud Service Providers:
Amazon Web Services Vs Microsoft Azure
| Parameters | AWS | Azure |
| Initiation | 2006 | 2010 |
| Market Share | 4x | x |
| Implementation | Less Options | More Experimentation Possible |
| Features | Widest Range Of Options | Good Range Of Options |
| App Hosting | AWS not as good as Azure | Azure Is Better |
| Development | Varied & Great Features | Varied & Great Features |
| IaaS Offerings | Good Market Hold | Better Offerings than AWS |
Answer D.
Explanation: This type of architecture would be a hybrid cloud. Why? Because we are using both, the public cloud, and your on premises servers i.e the private cloud. To make this hybrid architecture easy to use, wouldn’t it be better if your private and public cloud were all on the same network(virtually). This is established by including your public cloud servers in a virtual private cloud, and connecting this virtual cloud with your on premise servers using a VPN(Virtual Private Network).
Learn to design, develop, and manage a robust, secure, and highly available cloud-based solution for your organization’s needs with the Google Cloud Platform Course.
There are three primary types of cloud services: computing, storage, and networking.
Then there are AWS products built based on the three orders of all services. Computing services such as EC2, Elastic Beanstalk, Lambda, Auto-Scaling, and Lightsail are exemplifications. S3, Glacier, Elastic Block Storage, and the Elastic File System exemplify the storage. VPC, Amazon CloudFront, and Route53 are exemplifications of networking services.
Cloud computing has the following key characteristics:
AWS is an abbreviation for Amazon Web Services, which is a collection of remote computing services also known as Cloud Computing. This technology is also known as IaaS, or Infrastructure as a Service.
Some of the non-regional AWS services.
The following are the various layers operated by cloud architecture:
Cloud computing categories have various layers that include
There are several models for deploying cloud services:
Advantages:
Disadvantages:
The characteristics are as follows:
AWS’s key components are as follows:
For a detailed discussion on this topic, please refer to our EC2 AWS blog.
ec2-create-group CreateSecurityGroup
Answer B.
Explanation: A Security group is just like a firewall, it controls the traffic in and out of your instance. In AWS terms, the inbound and outbound traffic. The command mentioned is pretty straight forward, it says create security group, and does the same. Moving along, once your security group is created, you can add different rules in it. For example, you have an RDS instance, to access it, you have to add the public IP address of the machine from which you want to access the instance in its security group.
You should be using an On Demand instance for the same. Why? First of all, the workload has to be processed now, meaning it is urgent, secondly you don’t need them once your backlog is cleared, therefore Reserved Instance is out of the picture, and since the work is urgent, you cannot stop the work on your instance just because the spot price spiked, therefore Spot Instances shall also not be used. Hence On-Demand instances shall be the right choice in this case.
Which of the following will meet your requirements?
Answer: A
Explanation: Since the work we are addressing here is not continuous, a reserved instance shall be idle at times, same goes with On Demand instances. Also it does not make sense to launch an On Demand instance whenever work comes up, since it is expensive. Hence Spot Instances will be the right fit because of their low rates and no long term commitments.
Check out our AWS Certification Training in Top Cities
For a detailed, You can even check out the details of Migrating to AWS with the AWS Cloud Migration Training.
Starting, stopping and terminating are the three states in an EC2 instance, let’s discuss them in detail:
Answer A.
Explanation: The Instance tenancy attribute should be set to Dedicated Instance. The rest of the values are invalid.
Answer C.
Explanation: You are not charged, if only one Elastic IP address is attached with your running instance. But you do get charged in the following conditions:
First of all, let’s understand that Spot Instance, On-Demand instance and Reserved Instances are all models for pricing. Moving along, spot instances provide the ability for customers to purchase compute capacity with no upfront commitment, at hourly rates usually lower than the On-Demand rate in each region. Spot instances are just like bidding, the bidding price is called Spot Price. The Spot Price fluctuates based on supply and demand for instances, but customers will never pay more than the maximum price they have specified. If the Spot Price moves higher than a customer’s maximum price, the customer’s EC2 instance will be shut down automatically. But the reverse is not true, if the Spot prices come down again, your EC2 instance will not be launched automatically, one has to do that manually. In Spot and On demand instance, there is no commitment for the duration from the user side, however in reserved instances one has to stick to the time period that he has chosen.
Answer B.
Explanation: Reserved Instances is a pricing model, which is available for all instance types in EC2.
The processor state control consists of 2 states:
Now, why the C state and P state. Processors have cores, these cores need thermal headroom to boost their performance. Now since all the cores are on the processor the temperature should be kept at an optimal state so that all the cores can perform at the highest performance.
Now how will these states help in that? If a core is put into sleep state it will reduce the overall temperature of the processor and hence other cores can perform better. Now the same can be synchronized with other cores, so that the processor can boost as many cores it can by timely putting other cores to sleep, and thus get an overall performance boost.
Concluding, the C and P state can be customized in some EC2 instances like the c4.8xlarge instance and thus you can customize the processor according to your workload.
The network performance depends on the instance type and network performance specification, if launched in a placement group you can expect up to
First let’s understand what actually happens in a Hadoop cluster, the Hadoop cluster follows a master slave concept. The master machine processes all the data, slave machines store the data and act as data nodes. Since all the storage happens at the slave, a higher capacity hard disk would be recommended and since master does all the processing, a higher RAM and a much better CPU is required. Therefore, you can select the configuration of your machine depending on your workload. For e.g. – In this case c4.8xlarge will be preferred for master machine whereas for slave machine we can select i2.large instance. If you don’t want to deal with configuring your instance and installing hadoop cluster manually, you can straight away launch an Amazon EMR (Elastic Map Reduce) instance which automatically configures the servers for you. You dump your data to be processed in S3, EMR picks it from there, processes it, and dumps it back into S3.
AMIs(Amazon Machine Images) are like templates of virtual machines and an instance is derived from an AMI. AWS offers pre-baked AMIs which you can choose while you are launching an instance, some AMIs are not free, therefore can be bought from the AWS Marketplace. You can also choose to create your own custom AMI which would help you save space on AWS. For example if you don’t need a set of software on your installation, you can customize your AMI to do that. This makes it cost efficient, since you are removing the unwanted things.
Let’s understand this through an example, consider there’s a company which has user base in India as well as in the US.
Let us see how we will choose the region for this use case :
 So, with reference to the above figure the regions to choose between are, Mumbai and North Virginia. Now let us first compare the pricing, you have hourly prices, which can be converted to your per month figure. Here North Virginia emerges as a winner. But, pricing cannot be the only parameter to consider. Performance should also be kept in mind hence, let’s look at latency as well. Latency basically is the time that a server takes to respond to your requests i.e the response time. North Virginia wins again!
So, with reference to the above figure the regions to choose between are, Mumbai and North Virginia. Now let us first compare the pricing, you have hourly prices, which can be converted to your per month figure. Here North Virginia emerges as a winner. But, pricing cannot be the only parameter to consider. Performance should also be kept in mind hence, let’s look at latency as well. Latency basically is the time that a server takes to respond to your requests i.e the response time. North Virginia wins again!
So concluding, North Virginia should be chosen for this use case.
Depends! Every instance comes with its own private and public address. The private address is associated exclusively with the instance and is returned to Amazon EC2 only when it is stopped or terminated. Similarly, the public address is associated exclusively with the instance until it is stopped or terminated. However, this can be replaced by the Elastic IP address, which stays with the instance as long as the user doesn’t manually detach it. But what if you are hosting multiple websites on your EC2 server, in that case you may require more than one Elastic IP address.
There are several best practices to secure Amazon EC2. A few of them are given below:
The following steps can be used to update or downgrade a system with near-zero downtime:
First, you will have to Launch the EC2 console, then secondly, select the AMI Operating System. The next step is creating an instance using the new instance type; you need to install the updates and go to set up apps. Then check to determine if the instances are operational or not, and if everything is well, you will deploy the new instance and replace all the old ones. Now once everything is ready for installation, you can upgrade or downgrade the system with very little to no downtime
The image used to boot an EC2 instance is saved on the root device slice, which happens when an Amazon AMI launches a new EC2 case. This root device volume is supported by EBS or an instance store. In general, the lifetime of an EC2 instance does not affect the root device data stored on Amazon EBS.
The various instances available on Amazon EC2 General-purpose Instances:
Amazon EC2 now provides the option for customers to move from the current ‘instance count-based constraints’ to the new ‘vCPU Based restrictions.’ As a result, when launching a demand-driven mix of instance types, usage is assessed in terms of the number of vCPUs.
Setting up an autoscaling group to deploy new instances when an EC2 instance’s CPU consumption exceeds 80% and distributing traffic among instances via the deployment of an application load balancer and the designation of EC2 instances as target instances can do this.
Here’s how you can set them up:
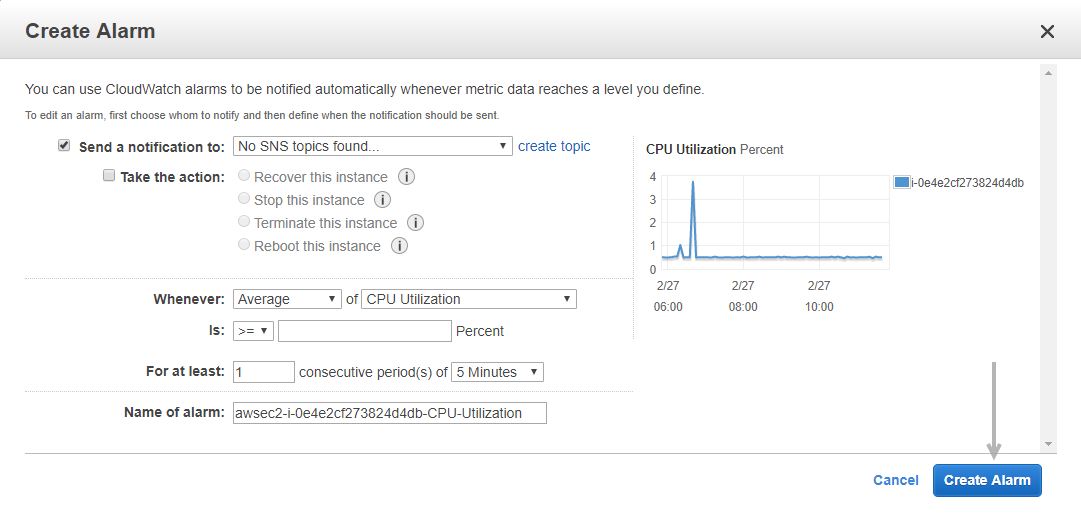 34. How do you recover/log in to an EC2 instance for which you have lost the key?
34. How do you recover/log in to an EC2 instance for which you have lost the key? If you have lost your key, follow the procedures below to recover an EC2 instance:
Step 1. Verify that the EC2Config service is operating.
Step 2. Detach the instance’s root volume.
Step 3. Connect the volume to a temporary instance
Step 4. Change the configuration file
Step 5. Restart the original instance.
Explanation: The following Storage Classes are accessible using Amazon S3:
37. How do you auto-delete old snapshots?
Explanation: Here’s how to delete outdated photos automatically:
Answer B.
Explanation: Rather than making changes to every object, its better to set the policy for the whole bucket. IAM is used to give more granular permissions, since this is a website, all objects would be public by default.
Answer D.
Explanation: Taking queue from the previous questions, this use case involves more granular permissions, hence IAM would be used here.
Yes, it can be used for instances with root devices backed by local instance storage. By using Amazon S3, developers have access to the same highly scalable, reliable, fast, inexpensive data storage infrastructure that Amazon uses to run its own global network of web sites. In order to execute systems in the Amazon EC2 environment, developers use the tools provided to load their Amazon Machine Images (AMIs) into Amazon S3 and to move them between Amazon S3 and Amazon EC2.
Another use case could be for websites hosted on EC2 to load their static content from S3.
For a detailed discussion on S3, please refer our S3 AWS blog.
Answer C.
Explanation: The fastest way to do it would be launching a new storage gateway instance. Why? Since time is the key factor which drives every business, troubleshooting this problem will take more time. Rather than we can just restore the previous working state of the storage gateway on a new instance.
Answer C.
Explanation: You would not use Snowball, because for now, the snowball service does not support cross region data transfer, and since, we are transferring across countries, Snowball cannot be used. Transfer Acceleration shall be the right choice here as it throttles your data transfer with the use of optimized network paths and Amazon’s content delivery network upto 300% compared to normal data transfer speed.
The data transfer can be increased in the following way:
EBS is a type of persistent storage that allows data to be recovered at a later time. When you save data to the EBS, it remains long after the EC2 instance has been terminated. Instance Store, on the other hand, is temporary storage that is physically tied to a host system. You cannot remove one instance and attach it to another using an Instance Store. Data in an Instance Store, unlike EBS, is lost if any instance is stopped or terminated.
To automate EC2 backups using EBS, perform the following steps:
Step 1. Get a list of instances and connect to AWS through API to get a list of Amazon EBS volumes that are associated to the instance locally.
Step 2. List each volume’s snapshots and give a retention time to each snapshot. Create a snapshot of each volume afterwards.
Step 3. Remove any snapshots that are older than the retention term.
A VPC is the most efficient way to connect to your cloud services from within your own data centre. When you link your datacenter to the VPC that contains your instances, each instance is allocated a private IP address that can be accessed from your datacenter. As a result, you may use public cloud services as if they were on your own private network.
Answer C.
Explanation: The best way of connecting to your cloud resources (for ex- ec2 instances) from your own data center (for eg- private cloud) is a VPC. Once you connect your datacenter to the VPC in which your instances are present, each instance is assigned a private IP address which can be accessed from your datacenter. Hence, you can access your public cloud resources, as if they were on your own network.
If you have numerous VPN connections, you may use the AWS VPN CloudHub to encrypt communication across locations. Here’s an illustration of how to link different sites to a VPC:
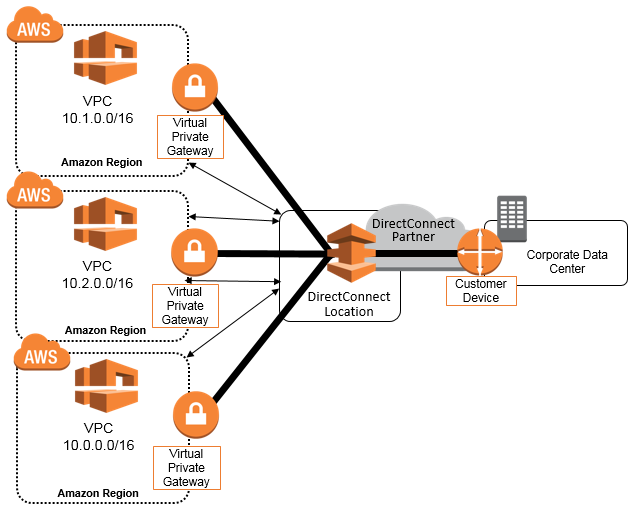
Here are some security products and features:
Security groups – serve as a firewall for EC2 instances, allowing you to regulate inbound and outgoing traffic at the instance level.
Network access control lists – It operates as a subnet-level firewall, managing inbound and outgoing traffic.
Flow logs – capture inbound and outgoing traffic from your VPC’s network interfaces.
Each Amazon Virtual Private Cloud may support up to 200 Subnets (VPC).
Yes, you can do this by establishing a VPN(Virtual Private Network) connection between your company’s network and your VPC (Virtual Private Cloud), this will allow you to interact with your EC2 instances as if they were within your existing network.
Primary private IP address is attached with the instance throughout its lifetime and cannot be changed, however secondary private addresses can be unassigned, assigned or moved between interfaces or instances at any point.
Answer B.
Explanation: If there is a network which has a large no. of hosts, managing all these hosts can be a tedious job. Therefore we divide this network into subnets (sub-networks) so that managing these hosts becomes simpler.
Answer B.
Explanation: Route Tables are used to route network packets, therefore in a subnet having multiple route tables will lead to confusion as to where the packet has to go. Therefore, there is only one route table in a subnet, and since a route table can have any no. of records or information, hence attaching multiple subnets to a route table is possible.
Answer B.
Explanation: CloudFront is a content delivery system, which caches data to the nearest edge location from the user, to reduce latency. If data is not present at an edge location, the first time the data may get transferred from the original server, but from the next time, it will be served from the cached edge.
Yes. Amazon CloudFront supports custom origins including origins from outside of AWS. With AWS Direct Connect, you will be charged with the respective data transfer rates.
If a backup AWS Direct connect has been configured, in the event of a failure it will switch over to the second one. It is recommended to enable Bidirectional Forwarding Detection (BFD) when configuring your connections to ensure faster detection and failover. On the other hand, if you have configured a backup IPsec VPN connection instead, all VPC traffic will failover to the backup VPN connection automatically. Traffic to/from public resources such as Amazon S3 will be routed over the Internet. If you do not have a backup AWS Direct Connect link or a IPsec VPN link, then Amazon VPC traffic will be dropped in the event of a failure.
We will now look at the next section in our AWS interview questions and answers, the Amazon Database.
Answer D.
Explanation: No, since the purpose of having a standby instance is to avoid an infrastructure failure (if it happens), therefore the standby instance is stored in a different availability zone, which is a physically different independent infrastructure.
Answer A.
Explanation: Provisioned IOPS deliver high IO rates but on the other hand it is expensive as well. Batch processing workloads do not require manual intervention they enable full utilization of systems, therefore a provisioned IOPS will be preferred for batch oriented workload.
For managing high amounts of traffic, as well as creating manual or automatic snapshots to restore data if the RDS instance fails, a bigger RDS instance type is necessary.
Vertical scaling and horizontal scaling are the two forms of scaling. Vertical scaling allows you to scale up your master database vertically with the click of a button. A database can only be scaled vertically, and the RDS may be resized in 18 different ways. Horizontal scaling, on the other hand, is beneficial for copies. These are read-only replicas that can only be performed with Amazon Aurora.
Answer D.
Explanation: No, Standby DB instance cannot be used with primary DB instance in parallel, as the former is solely used for standby purposes, it cannot be used unless the primary instance goes down.
The task is to run an hourly batch process and read data from every region to compute cross-regional reports which will be distributed to all the branches. This should be done in the shortest time possible. How will you build the DB architecture in order to meet the requirements?
Answer A.
Explanation: For this we will take an RDS instance as a master, because it will manage our database for us and since we have to read from every region, we’ll put a read replica of this instance in every region where the data has to be read from. Option C is not correct since putting a read replica would be more efficient than putting a snapshot, a read replica can be promoted if needed to an independent DB instance, but with a Db snapshot it becomes mandatory to launch a separate DB Instance.
Yes. You can run more than one Single-AZ Micro database instance, that too for free! However, any use exceeding 750 instance hours, across all Amazon RDS Single-AZ Micro DB instances, across all eligible database engines and regions, will be billed at standard Amazon RDS prices. For example: if you run two Single-AZ Micro DB instances for 400 hours each in a single month, you will accumulate 800 instance hours of usage, of which 750 hours will be free. You will be billed for the remaining 50 hours at the standard Amazon RDS price.
For a detailed discussion on this topic, please refer our RDS AWS blog.
Answer B,C.
Explanation: DynamoDB is a fully managed NoSQL database service. DynamoDB, therefore can be fed any type of unstructured data, which can be data from e-commerce websites as well, and later, an analysis can be done on them using Amazon Redshift. We are not using Elastic MapReduce, since a near real time analyses is needed.
Yes. When using the GetItem, BatchGetItem, Query or Scan APIs, you can define a Projection Expression to determine which attributes should be retrieved from the table. Those attributes can include scalars, sets, or elements of a JSON document.
Answer D.
Explanation: DynamoDB has the ability to scale more than RDS or any other relational database service, therefore DynamoDB would be the apt choice.
When you delete a DB instance, you have an option of creating a final DB snapshot, if you do that you can restore your database from that snapshot. RDS retains this user-created DB snapshot along with all other manually created DB snapshots after the instance is deleted, also automated backups are deleted and only manually created DB Snapshots are retained.
Answer C,D.
Explanation: If all your JSON data have the same fields eg [id,name,age] then it would be better to store it in a relational database, the metadata on the other hand is unstructured, also running relational joins or complex updates would work on DynamoDB as well.
You can load the data in the following two ways:
You may plan DB instance updates, database engine version upgrades, and software patching using the RDS maintenance window. Only upgrades for security and durability are scheduled automatically. The maintenance window is set to 30 minutes by default, and the DB instance will remain active throughout these events, but with somewhat reduced performance.
Answer C.
Explanation: Since our work requires the data to be extracted and analyzed, to optimize this process a person would use provisioned IO, but since it is expensive, using a ElastiCache memoryinsread to cache the results in the memory can reduce the provisioned read throughput and hence reduce cost without affecting the performance.
Answer A,C.
Explanation: Since it does a lot of read writes, provisioned IO may become expensive. But we need high performance as well, therefore the data can be cached using ElastiCache which can be used for frequently reading the data. As for RDS since read contention is happening, the instance size should be increased and provisioned IO should be introduced to increase the performance.
Answer C.
Explanation: A Redshift cluster would be preferred because it easy to scale, also the work would be done in parallel through the nodes, therefore is perfect for a bigger workload like our use case. Since each month 4 GB of data is generated, therefore in 2 year, it should be around 96 GB. And since the servers will be increased to 100K in number, 96 GB will approximately become 96TB. Hence option C is the right answer.
Answer B.
Explanation: You will choose an application load balancer, since it supports path based routing, which means it can take decisions based on the URL, therefore if your task needs image rendering it will route it to a different instance, and for general computing it will route it to a different instance.
Scalability is the ability of a system to increase its hardware resources to handle the increase in demand. It can be done by increasing the hardware specifications or increasing the processing nodes.
Elasticity is the ability of a system to handle increase in the workload by adding additional hardware resources when the demand increases(same as scaling) but also rolling back the scaled resources, when the resources are no longer needed. This is particularly helpful in Cloud environments, where a pay per use model is followed.
To add an existing instance to a new Auto Scaling group, follow these steps:
Step1. Launch the EC2 console.
Step2. Select your instance from the list of Instances.
Step3. Navigate to Actions -> Instance Settings -> Join the Auto Scaling Group
Step4. Choose a new Auto Scaling group.
Step5. Join this group to the Instance.
Step6. If necessary, modify the instance.
Step7. Once completed, the instance may be successfully added to a new Auto Scaling group.
Answer D.
Explanation: Auto scaling tags configuration, is used to attach metadata to your instances, to change the instance type you have to use auto scaling launch configuration.
Answer A.
Explanation:Creating alone an autoscaling group will not solve the issue, until you attach a load balancer to it. Once you attach a load balancer to an autoscaling group, it will efficiently distribute the load among all the instances. Option B – CloudFront is a CDN, it is a data transfer tool therefore will not help reduce load on the EC2 instance. Similarly the other option – Launch configuration is a template for configuration which has no connection with reducing loads.
A Classic Load Balancer is ideal for simple load balancing of traffic across multiple EC2 instances, while an Application Load Balancer is ideal for microservices or container-based architectures where there is a need to route traffic to multiple services or load balance across multiple ports on the same EC2 instance.
For a detailed discussion on Auto Scaling and Load Balancer, please refer our EC2 AWS blog.
Answer B.
Explanation: Connection draining is a service under ELB which constantly monitors the health of the instances. If any instance fails a health check or if any instance has to be patched with a software update, it pulls all the traffic from that instance and re routes them to other instances.
Answer B.
Explanation: When ELB detects that an instance is unhealthy, it starts routing incoming traffic to other healthy instances in the region. If all the instances in a region becomes unhealthy, and if you have instances in some other availability zone/region, your traffic is directed to them. Once your instances become healthy again, they are re routed back to the original instances.
Answer B.
Explanation: Lifecycle hooks are used for putting wait time before any lifecycle action i.e launching or terminating an instance happens. The purpose of this wait time, can be anything from extracting log files before terminating an instance or installing the necessary softwares in an instance before launching it.
Answer B.
Explanation: Auto Scaling allows you to suspend and then resume one or more of the Auto Scaling processes in your Auto Scaling group. This can be very useful when you want to investigate a configuration problem or other issue with your web application, and then make changes to your application, without triggering the Auto Scaling process.
CloudTrail is a service that logs every request made to the Amazon Route 53 API by an AWS account, including those made by IAM users. CloudTrail stores these requests’ log files to an Amazon S3 bucket. CloudTrail collects data on all requests. CloudTrail log files contain information that may be used to discover which requests were submitted to Amazon Route 53, the IP address from which the request was sent, who issued the request, when it was sent, and more.
AWS CloudTrail logs user API activity on your account and provides you with access to the data. CloudTrail provides detailed information on API activities such as the caller’s identity, the time of the call, request arguments, and response elements. AWS Config, on the other hand, saves point-in-time configuration parameters for your AWS resources as Configuration Items (CIs).
A CI may be used to determine what your AWS resource looks like at any given time. Using CloudTrail, on the other hand, you can instantly determine who made an API request to alter the resource. Cloud Trail may also be used to determine if a security group was wrongly setup.
Answer A.
Explanation: Any rule specified in an EC2 Security Group applies immediately to all the instances, irrespective of when they are launched before or after adding a rule.
Answer A.
Explanation: Route 53 record sets are common assets therefore there is no need to replicate them, since Route 53 is valid across regions
Answer A.
Explanation: AWS CloudTrail provides inexpensive logging information for load balancer and other AWS resources This logging information can be used for analyses and other administrative work, therefore is perfect for this use case.
Answer A.
Explanation: AWS CloudTrail has been designed for logging and tracking API calls. Also this service is available for storage, therefore should be used in this use case.
Answer B,C.
Explanation: Cloudtrail is not enabled for all the services and is also not available for all the regions. Therefore option B is correct, also the logs can be delivered to your S3 bucket, hence C is also correct.
CloudTrail files are delivered according to S3 bucket policies. If the bucket is not configured or is misconfigured, CloudTrail might not be able to deliver the log files.
You will need to get a list of the DNS record data for your domain name first, it is generally available in the form of a “zone file” that you can get from your existing DNS provider. Once you receive the DNS record data, you can use Route 53’s Management Console or simple web-services interface to create a hosted zone that will store your DNS records for your domain name and follow its transfer process. It also includes steps such as updating the nameservers for your domain name to the ones associated with your hosted zone. For completing the process you have to contact the registrar with whom you registered your domain name and follow the transfer process. As soon as your registrar propagates the new name server delegations, your DNS queries will start to get answered.
The most important services you may utilise are Amazon CloudWatch Logs, which you can store in Amazon S3 and then display using Amazon Elastic Search. To transfer data from Amazon S3 to Amazon ElasticSearch, you can utilise Amazon Kinesis Firehose.
Ans: Amazon Simple Notification Service (SNS) is a web service that manages user notifications sent from any cloud platform. From any cloud platform, manage and distribute messages or notifications to users and consumers.
Amazon Simple Queue Service (SQS) administers the queue service, which allows users to move data whether it is running or active.
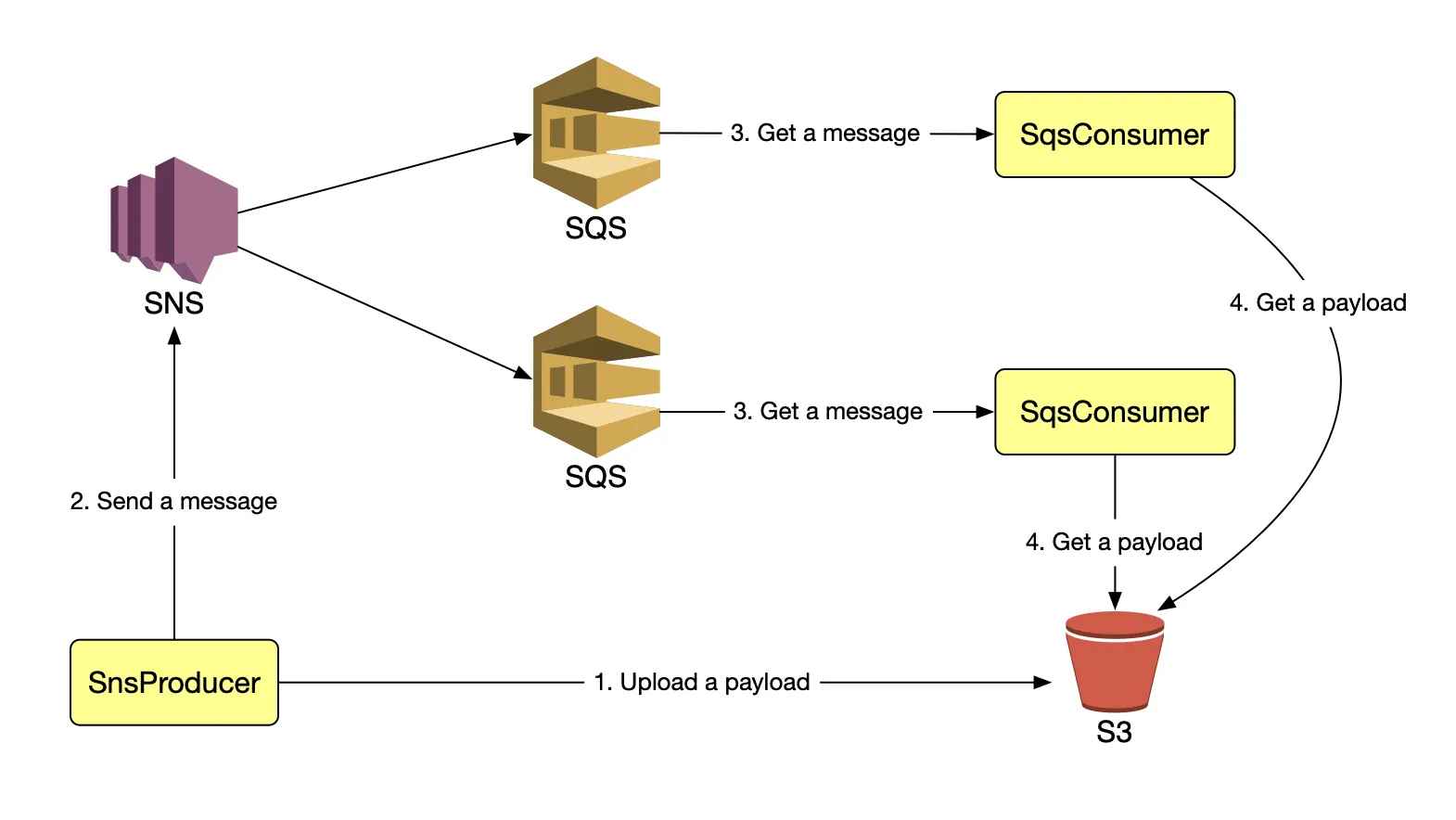 97. Which of the following services you would not use to deploy an app?
97. Which of the following services you would not use to deploy an app?Answer B.
Explanation: Lambda is used for running server-less applications. It can be used to deploy functions triggered by events. When we say serverless, we mean without you worrying about the computing resources running in the background. It is not designed for creating applications which are publicly accessed.
The following are some distinctions between AWS CloudFormation and AWS Elastic Beanstalk:
AWS CloudFormation assists you in provisioning and describing all infrastructure resources in your cloud environment. AWS Elastic Beanstalk, on the other hand, provides an environment that makes it simple to install and execute cloud applications.
AWS CloudFormation meets the infrastructure requirements of a wide range of applications, including legacy applications and existing corporate applications. AWS Elastic Beanstalk, on the other hand, is integrated with developer tools to assist you in managing the lifespan of your applications.
Answer A.
Explanation: Elastic Beanstalk prepares a duplicate copy of the instance, before updating the original instance, and routes your traffic to the duplicate instance, so that, incase your updated application fails, it will switch back to the original instance, and there will be no downtime experienced by the users who are using your application.
AWS Beanstalk apps provide a built-in method for preventing infrastructure problems. If an Amazon EC2 instance dies for whatever reason, Beanstalk will instantly start a new instance using Auto Scaling. Beanstalk can detect if your application is not responding to the custom link.
AWS Elastic Beanstalk is an application management platform while OpsWorks is a configuration management platform. BeanStalk is an easy to use service which is used for deploying and scaling web applications developed with Java, .Net, PHP, Node.js, Python, Ruby, Go and Docker. Customers upload their code and Elastic Beanstalk automatically handles the deployment. The application will be ready to use without any infrastructure or resource configuration.
In contrast, AWS Opsworks is an integrated configuration management platform for IT administrators or DevOps engineers who want a high degree of customization and control over operations.
AWS Beanstalk applications have a system in place for avoiding failures in the underlying infrastructure. If an Amazon EC2 instance fails for any reason, Beanstalk will use Auto Scaling to automatically launch a new instance. Beanstalk can also detect if your application is not responding on the custom link, even though the infrastructure appears healthy, it will be logged as an environmental event( e.g a bad version was deployed) so you can take an appropriate action.
For a detailed discussion on this topic, please refer Lambda AWS blog.
OpsWorks and CloudFormation both support application modelling, deployment, configuration, management and related activities. Both support a wide variety of architectural patterns, from simple web applications to highly complex applications. AWS OpsWorks and AWS CloudFormation differ in abstraction level and areas of focus.
AWS CloudFormation is a building block service which enables customer to manage almost any AWS resource via JSON-based domain specific language. It provides foundational capabilities for the full breadth of AWS, without prescribing a particular model for development and operations. Customers define templates and use them to provision and manage AWS resources, operating systems and application code.
In contrast, AWS OpsWorks is a higher level service that focuses on providing highly productive and reliable DevOps experiences for IT administrators and ops-minded developers. To do this, AWS OpsWorks employs a configuration management model based on concepts such as stacks and layers, and provides integrated experiences for key activities like deployment, monitoring, auto-scaling, and automation. Compared to AWS CloudFormation, AWS OpsWorks supports a narrower range of application-oriented AWS resource types including Amazon EC2 instances, Amazon EBS volumes, Elastic IPs, and Amazon CloudWatch metrics.
Answer C.
Explanation: AWS OpsWorks is a configuration management solution that allows you to use Puppet or Chef to setup and run applications in a cloud organisation. AWS OpsWorks Stacks and AWS OpsWorks for Chef Automate allow you to leverage Chefcookbooks and solutions for configuration management, whereas AWS OpsWorks for Puppet Enterprise allows you to set up an AWS Puppet Enterprise master server. Puppet provides a suite of tools for enforcing desirable infrastructure states and automating on-demand operations.
Answer C.
Explanation: The key created and the data to be encrypted should be in the same region. Hence the approach taken here to secure the data is incorrect.
Answer C.
Explanation: The OpsWorks service can meet the need. This need is supported by the AWS attestation listed below AWS OpsWorks Stacks allows you to manage AWS and on- demesne apps and waiters. You may represent your operation as a mound with several layers similar as cargo balancing, database, and operation garçon using OpsWorks Stacks. In each league, you may emplace and configure Amazon EC2 cases or link fresh coffers similar as Amazon RDS databases.
Answer B.
Explanation: Amazon CloudWatch is a cloud monitoring tool and hence this is the right service for the mentioned use case. The other options listed here are used for other purposes for example route 53 is used for DNS services, therefore CloudWatch will be the apt choice.
When an event like this occurs, the “automatic rollback on error” feature is enabled, which causes all the AWS resources which were created successfully till the point where the error occurred to be deleted. This is helpful since it does not leave behind any erroneous data, it ensures the fact that stacks are either created fully or not created at all. It is useful in events where you may accidentally exceed your limit of the no. of Elastic IP addresses or maybe you may not have access to an EC2 AMI that you are trying to run etc.
Any of the following tools can be used:
Overwhelmed with all these questions? Below are the top technologies to learn in 2023
We at Edureka are here to help you with every step on your journey, to becoming an AWS Solution Architect; therefore besides the AWS Interview Questions and answers, we have come up with a curriculum that covers exactly what you would need to crack the Solution Architect Exam! You can have a look at the course details from the AWS training in Chennai.
I hope you benefitted from these AWS Interview Questions. The topics that you learned in this blog are the most sought-after skill sets that recruiters look for in an AWS Solution Architect Professional. I have tried touching up on AWS interview questions and answers for freshers and for people with 3-5 years of experience. However, for a more detailed study on AWS, you can refer our AWS Tutorial.
Got a question for us? Please mention it in the comments section of this AWS Interview Questions and we will get back to you.
Related Posts:
| Course Name | Date | |
|---|---|---|
| AWS Solutions Architect Certification Training Course | Class Starts on 28th January,2023 28th January SAT&SUN (Weekend Batch) | View Details |
| AWS Solutions Architect Certification Training Course | Class Starts on 30th January,2023 30th January MON-FRI (Weekday Batch) | View Details |
| AWS Solutions Architect Certification Training Course | Class Starts on 25th February,2023 25th February SAT&SUN (Weekend Batch) | View Details |
































 REGISTER FOR FREE WEBINAR
REGISTER FOR FREE WEBINAR  Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP










Hi,
Good Interview Questions and will useful to Aws Jobs. Find Aws jobs in peeljobs.com. Peeljobs is one of the best job portal in India. Job seekers can create their account or they can log in with their social networking sites like Facebook, G+, Twitter, LinkedIn, GitHub. Find Aws jobs for freshers and Experienced
For this question Q: A company is deploying a new two-tier web application in AWS. The company has limited staff and requires high availability, and the application requires complex queries and table joins. Which configuration provides the solution for the company’s requirements?
Dynamo DB is incorrect answer. It should be RDS with MySQL in Multi-AZ configuration. Because Dynamo DB is not suitable for complex queries and Table Joins..
AWS Solution Architect Associate Question Answers
Here is some sample question and answers!
A group can contain many users. Can a user belong to multiple groups?
A. No
C. Yes always
B. Yes but only in VPC
D. Yes but only if they are using two factor authentication
Answer: B
A group can contain many users. Can a user belong to multiple groups?
A. No
B. Yes but only in VPC
C. Yes always
D. Yes but only if they are using two factor authentication
Answer: C
For which of the following use cases are Simple Workflow Service (SWF) and Amazon EC2 an appropriate solution? Choose 2 answers!
A. Using as an endpoint to collect thousands of data points per hour from a distributed fleet of sensors
B. Managing a multi-step and multi-decision checkout process of an e-commerce website
C. Orchestrating the execution of distributed and auditable business processes
D. Using as an SNS (Simple Notification Service) endpoint to trigger execution of video transcoding jobs
E. Using as a distributed session store for your web application
Answer: A,B
AWS Solution Architect Associate exam dumps
Step-by-step video tutorials that helps you in understanding the concepts and clearing the certification exam.
>> http://www.theonlinefortune.com/aws-certification-course/
https://uploads.disquscdn.com/images/eef0d8525eec2a709a188387974fc6e796c10c2915771937096b6085fbcd0fce.jpg
Hi and thanks a lot… but some answers seems strange, for example :
41. Which of the following use cases are suitable for Amazon DynamoDB? Choose 2 answers
A. Managing web sessions.
B. Storing JSON documents.
C. Storing metadata for Amazon S3 objects.
D. Running relational joins and complex updates.
Answer C,D.
For me correct answers are A, B and C (DynamoDB for relational joins ???)
Yeah I agree .. it should be A, B, and C
Hey Muhammad, thanks for checking out our blog.
Yes, Dynanmo Db isn’t used for any Complex relational queries. D shouldn’t be in the answer.
You can find out more here:
FAQ 8, Para 2 : https://aws.amazon.com/dynamodb/faqs/
Hope this helps. Cheers!
Hey Romain, thanks for checking out our blog.
Yes, Dynanmo Db isn’t used for any Complex relational queries. D shouldn’t be in the answer.
You can find out more here:
FAQ 8, Para 2 : https://aws.amazon.com/dynamodb/faqs/
Hope this helps. Cheers!
Get actual AWS Solution Architect Associate dumps from the leading organization Dumps4Download.us
Hi
I want to learn cloud computing, my background is SAP Basis admin for 2 yrs, I
know nothing about AWS. I am reading about it since a week. What would be
your professional advice? How long will it take to excel it, how about
the job market?
I have done my Bachelor of Arts then PG Dip in Computer
Applications.
I just want to drive my career uniquely. After a brief discussion about AWS, with one
of my friend who is a junior SAP Architect, I thought this is my career.
After I gone through Amazon site I understood that the
Solution architect – Associate is the first step in certification right? Please advice on AWS career plan and the
areas where I need to accumulate knowledge.
Hope for your valued response.
Thank you
Anand
Hey Anand, thanks for checking out our blog. With regard to your query, yes, you can go ahead with learning AWS considering your background. The time required to learn Cloud computing with AWS entirely depends on the time you spend to learn it. However, if you opt for a structured training, you should be ready in a month’s time. When we say ready, it means you will know about most components and how they work. Post that, you will need to spend time on trying out some POC’s to get skilled & become confident in the services provided by AWS. Coming to your last query, your first step should be to get into a structured training so that you are ready before you take your AWS Solution Archtect – Associate exam. And, yes, this is the first exam you need to clear before you can attempt the next one. Hope this helps. Cheers!
These questions are very helpful thank you for shearing this kind of information.
AWS Solution architect Associate dumps
Explain BGP Border Gateway Protocol
Denial Service Attack
Proxy versus Reverse Proxy
Types of Loadbalancer
Which algorithm does an Elastic Load Balancer use?
HAPROXY VS NGINX (Comparing Load Balancing Options: Nginx vs. HAProxy vs. AWS ELB – See more at: http://www.mervine.net/comparing-load-balancing#sthash.jgaYgVC8.dpuf)
MYSql Storage Engine
MySQL Architecture
Hadoop Acrchitecture & HDFS, Named Node, Data Node, MapReduce
Web 3 tier Architecture
RPO & RTO in disaster Recovery
Bandwidth Throughput Latency
Bandwidth MTU
OLAP and OLTP
Difference between SAN & NAS
Blue Green Deployment
Replication technologies available
Difference between XML & JSON
What is CI(continuous integration) tool and example
Docker
Container
Difference between Docker & Container
What is Memcache
Details of VLAN
Content Delivery/Distribution Network(CDN)
MS SQL to Oracle Migration
Platforms (Power, Sparc, Intel X86)
How do you perform caching?
Do you know EMR and Redshift?
What is the biggest mistake you have made?
What is EBS?
How do you architect a design that is fault tolerant?
What are the services you have used in AWS?
What are some web protocols?
What is TCP and UDP?