






Azure Data Engineer Associate Certification C ...
- 2k Enrolled Learners
- Weekend
- Live Class
(550)
In this blog, I am going to talk about HDFS 2.x High Availability Cluster Architecture and the procedure to set up an HDFS High Availability cluster. This is an important part of the Big Data course. The order in which the topics have been covered in this blog are as follows:
The concept of High Availability cluster was introduced in Hadoop 2.x to solve the single point of failure problem in Hadoop 1.x. As you know from my previous blog that the HDFS Architecture follows Master/Slave Topology where NameNode acts as a master daemon and is responsible for managing other slave nodes called DataNodes. This single Master Daemon or NameNode becomes a bottleneck. Although, the introduction of Secondary NameNode did prevent us from data loss and offloading some of the burden of the NameNode but, it did not solve the availability issue of the NameNode.
If you consider the standard configuration of HDFS cluster, the NameNode becomes a single point of failure. It happens because the moment the NameNode becomes unavailable, the whole cluster becomes unavailable until someone restarts the NameNode or brings a new one.
The reasons for unavailability of NameNode can be:
In either of the above cases, we have a downtime where we are not able to use the HDFS cluster which becomes a challenge.
Let us understand that how HDFS HA Architecture solved this critical problem of NameNode availability:
The HA architecture solved this problem of NameNode availability by allowing us to have two NameNodes in an active/passive configuration. So, we have two running NameNodes at the same time in a High Availability cluster:

If one NameNode goes down, the other NameNode can take over the responsibility and therefore, reduce the cluster down time. The standby NameNode serves the purpose of a backup NameNode (unlike the Secondary NameNode) which incorporate failover capabilities to the Hadoop cluster. Therefore, with the StandbyNode, we can have automatic failover whenever a NameNode crashes (unplanned event) or we can have a graceful (manually initiated) failover during the maintenance period.
There are two issues in maintaining consistency in the HDFS High Availability cluster:
Now, you know that in HDFS HA Architecture, we have two NameNodes running at the same time. So, we can implement the Active and Standby NameNode configuration in following two ways:
Let us understand these two ways of implementation taking one at a time:

Now, as discussed earlier, it is very important to ensure that there is only one Active NameNode at a time. So, fencing is a process to ensure this very property in a cluster.

Failover is a procedure by which a system automatically transfers control to secondary system when it detects a fault or failure. There are two types of failover:
Graceful Failover: In this case, we manually initiate the failover for routine maintenance.
Automatic Failover: In this case, the failover is initiated automatically in case of NameNode failure (unplanned event).
Apache Zookeeper is a service that provides the automatic failover capability in HDFS High Availabilty cluster. It maintains small amounts of coordination data, informs clients of changes in that data, and monitors clients for failures. Zookeeper maintains a session with the NameNodes. In case of failure, the session will expire and the Zookeeper will inform other NameNodes to initiate the failover process. In case of NameNode failure, other passive NameNode can take a lock in Zookeeper stating that it wants to become the next Active NameNode.
The ZookeerFailoverController (ZKFC) is a Zookeeper client that also monitors and manages the NameNode status. Each of the NameNode runs a ZKFC also. ZKFC is responsible for monitoring the health of the NameNodes periodically.
Now that you have understood what is High Availability in a Hadoop cluster, it’s time to set it up. To set up High Availability in Hadoop cluster you have to use Zookeeper in all the nodes.
The daemons in Active NameNode are:
The daemons in Standby NameNode are:
The daemons in DataNode are:
If you wish to master HDFS and Hadoop, check out the specially curated Big Data certification course by Edureka. Click on the button below to get started.
![]()
You have to first set up the Java and host names of each node.
| Virtual machine | IP address | Host name |
| Active NameNode | 192.168.1.81 | nn1.cluster.com or nn1 |
| Standby NameNode | 192.168.1.58 | nn2.cluster.com or nn2 |
| DataNode | 192.168.1.82 | dn1.cluster.com or dn1 |
Download the Hadoop and Zookeeper binary tar file, extract the files to edit configuration files.
Command : wget https://archive.apache.org/dist/zookeeper/zookeeper-3.4.6/zookeeper-3.4.6.tar.gz

Untar the zookeeper-3.4.6.tar.gz
Command: tar –xvf zookeeper-3.4.6.tar.gz

Download the stable Hadoop binary tar to from Apache Hadoop site.
Command: wget https://archive.apache.org/dist/hadoop/core/hadoop-2.6.0/hadoop-2.6.0.tar.gz

Extract the Hadoop tar ball.
Command: tar –xvf hadoop-2.6.0.tar.gz

Add the Hadoop, Zookeeper and paths to .bashrc file.
Open the .bashrc file.
Command: sudo gedit ~/.bashrc
Add the below paths:
export HADOOP_HOME=< Path to your Hadoop-2.6.0 directory>
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
export JAVA_HOME=<Path to your Java Directory>
export ZOOKEEPER_HOME =<Path to your Zookeeper Directory>
export PATH=$PATH: $JAVA_HOME/bin: $HADOOP_HOME/bin: $HADOOP_HOME/sbin:$ZOOKEEPER_HOME/bin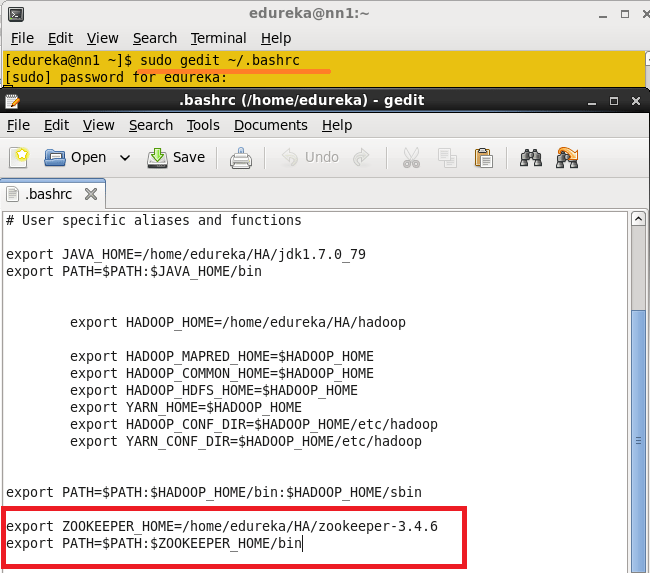
Enable the SSH in all the node.
Generate the SSH key in all the nodes.
Command: ssh-keygen –t rsa (This Step in all the Nodes)

Don’t give any path to the Enter file to save the key and don’t give any passphrase. Press enter button.
Generate the ssh key process in all the nodes.
Once ssh key is generated, you will get the public key and private key.
The .ssh key Directory should contain the Permission 700 and all the keys inside the .ssh directory should contain the permissions 600.

Change the directory to .ssh and change the permission of files to 600

You have to copy the Name nodes ssh public key to all the nodes.
In Active Namenode, copy the id_rsa.pub using cat command.
Command: cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys

Copy the NameNode public key to all the nodes using ssh-copy-id command.
Command: ssh-copy-id –i .ssh/id_rsa.pub [email protected]

Copy NameNode public key to data node.
Command: ssh-copy-id –i .ssh/id_rsa.pub [email protected]

Restart the sshd service in all the nodes.
Command: sudo service sshd restart (Do in all the nodes)
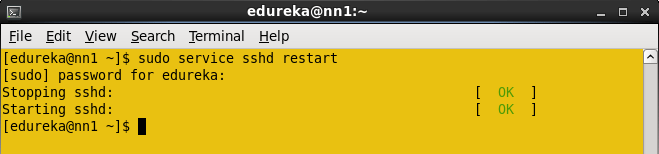
Now you can login to the any node from Namenode without any authentication.
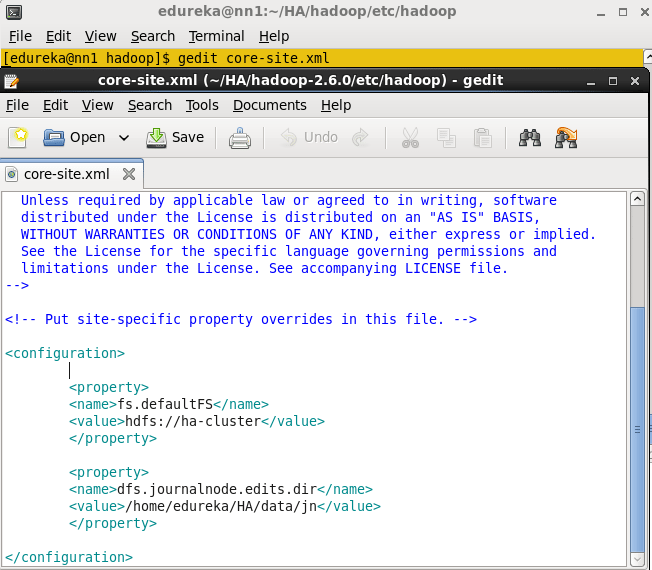
Open the core-site.xml file from the Active Name node and add the below properties.
Open hdfs-site.xml file in Active Namenode. Add the below Properties.
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/edureka/HA/data/namenode</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>ha-cluster</value>
</property>
<property>
<name>dfs.ha.namenodes.ha-cluster</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ha-cluster.nn1</name>
<value>nn1.cluster.com:9000</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ha-cluster.nn2</name>
<value>nn2.cluster.com:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.ha-cluster.nn1</name>
<value>nn1.cluster.com:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.ha-cluster.nn2</name>
<value>nn2.cluster.com:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://nn1.cluster.com:8485;nn2.cluster.com:8485;dn1.cluster.com:8485/ha-cluster</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.ha-cluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value> nn1.cluster.com:2181,nn2.cluster.com:2181,dn1.cluster.com:2181 </value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/edureka/.ssh/id_rsa</value>
</property>Change the directory to zookeeper’s conf directory.
Command: cd zookeeper-3.4.6/conf

In a conf directory you have zoo_sample.cfg file, create the zoo.cfg using zoo_sample.cfg file.
Command: cp zoo_sample.cfg zoo.cfg

Create the directory in any location and use this directory to store the zookeeper data.
Command: mkdir <path, where you want to store the zookeeper files>

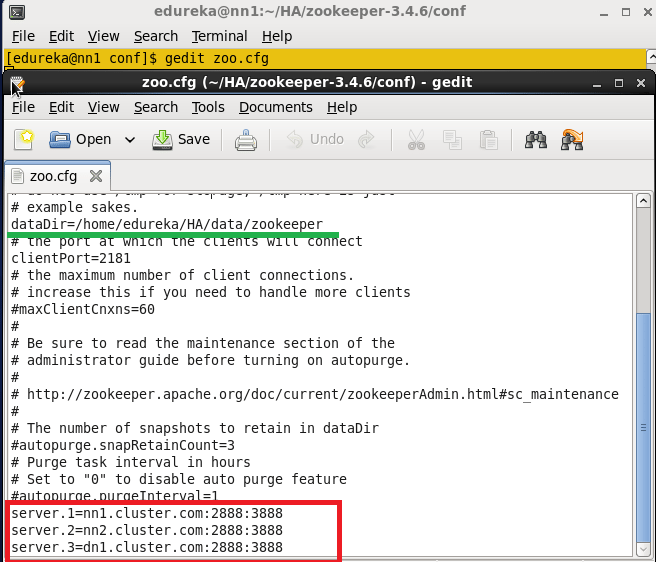
Open the zoo.cfg file.
Command: gedit zoo.cfg
Add the directory path that is created in above step to the dataDir property and add the below details regarding remaining node, in the zoo.cfg file.
Server.1=nn1.cluster.com:2888:3888
Server.2=nn2.cluster.com:2888:3888
Server.3=dn1.cluster.com:2888:3888
Now copy the Java and Hadoop-2.6.0, zookeeper-3.4.6 directories, and .bashrc file to all the nodes (Standby name node, Data node) using scp command.
Command: scp –r <path of directory> edureka@<ip address>:<path where you need to copy>

Similarly, copy the .bashrc file and zookeeper directory to all the nodes and change the environment variables in each according to the respective node.
In a data node, create any directory where you need to store the HDFS blocks.
In a data node, you have to add the dfs.datanode.data.dir properties.
In my case, I created datanode directory to store the blocks.

Change the permission to data node directory.

Open the HDFS-site.xml file, add this Datanode directory path in dfs.datanode.data.dir property.
Note: Keep all the properties that are copied from the Active namenode; add dfs.datanode.data.dir one extract property in namenode.
<property>
<name> dfs.datanode.data.dir</name>
<value>/home/edureka/HA/data/datanode</value>
</property>In Active namenode, change the directory where you want to store the zookeeper configuration file (dataDir property path).
Create the myid file inside the directory and add numeric 1 to the file and save the file.
Command: vi myid
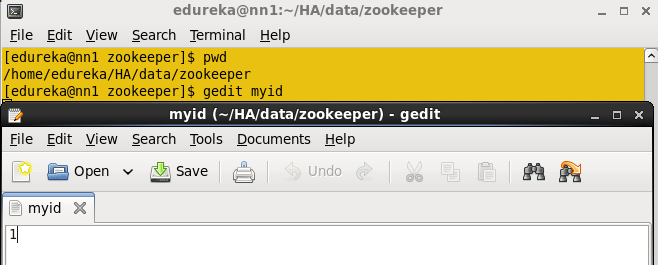
In a standby namenode change the directory where you want to store the zookeeper configuration file (dataDir property path).
Create the myid file inside the directory and add numeric 2 to the file and save the file.
In a data node, change the directory where you want to store the zookeeper configuration file (dataDir property path).
Create the myid file inside the directory and add numeric 3 to the file and save the file.
Start the Journalnode in all the three nodes.
Command: hadoop-daemon.sh start journalnode
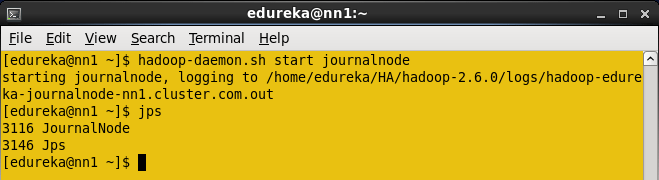
When you enter jps command, you will see the JournalNode daemon in all the nodes.
Format the Active namenode.
Command: HDFS namenode -format

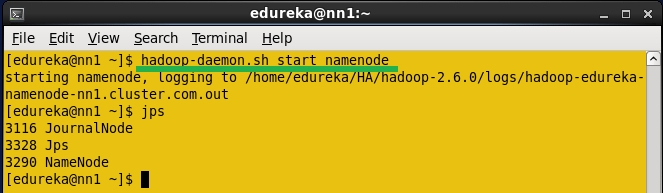
Start the Namenode daemon in Active namenode.
Command: hadoop-daemon.sh start namenode
Copy the HDFS Meta data from active name node to standby namenode.
Command: HDFS namenode -bootstrapStandby
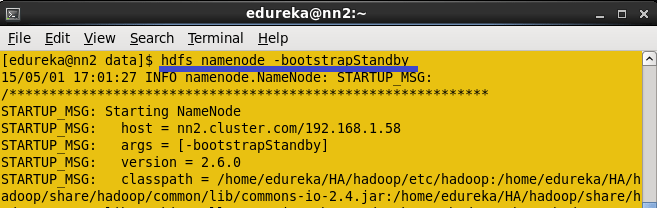
Once you run this command, you will get the information from which node and location the meta data is copying and whether it is copying successfully or not.
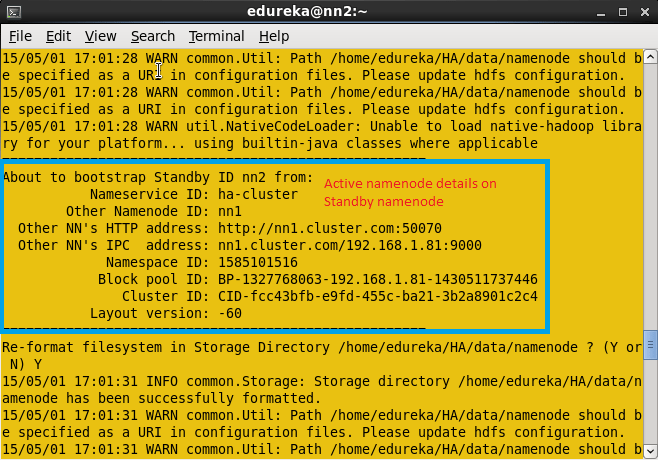
Once Meta data is copied from Active namenode to standby namenode, you will get the message shown below in the screenshot.
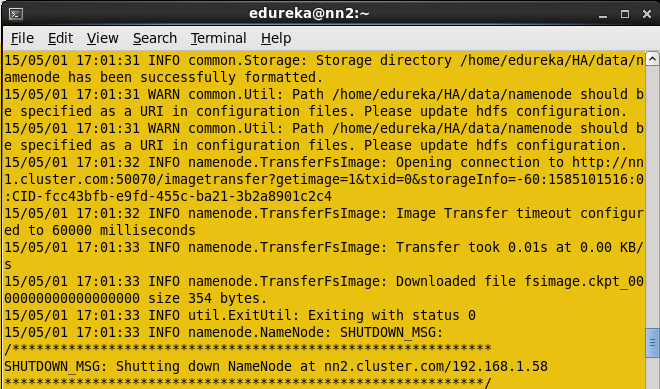
Start the namenode daemon in Standby namenode machine.
Command: hadoop-daemon.sh start namenode
Now start the Zookeeper service in all the three nodes.
Command: zkServer.sh start (Run this command in all the nodes)
In Active Namenode:

In Standby Namenode:

In Data node:

After running the Zookeeper server, enter JPS command. In all the nodes you will see the QuorumPeerMain service.
Start the Data node daemon in Data node machine.
Command: hadoop-daemon.sh start datanode
Start the Zookeeper fail over controller in Active name node and standby name node.
Format the zookeeper fail over controller in Active namenode.
Command: HDFS zkfc –formatZK
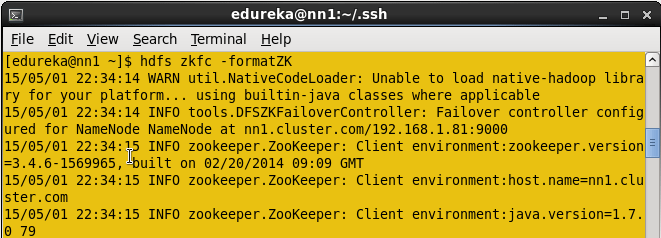
Start the ZKFC in Active namenode.
Command: hadoop-daemon.sh start zkfc
Enter jps command to check the DFSZkFailoverController daemons.

Format the zookeeper fail over controller in Standby namenode.
Command: hdfs zkfc –formatZK
Start the ZKFC in Standby namenode.
Command: hadoop-daemon.sh start zkfc
Enter jps command to check the DFSZkFailoverController daemons.
Now check the status of each Namenode, which node is Active or which node is on Standby by using the below command.
Command: hdfs haadmin –getServiceState nn1
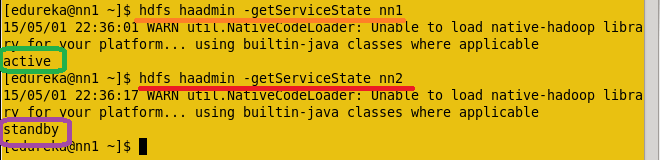
Now Check the status of each Namenode using the web browser.
Open the Web browser and enter the below URL.
<IP Address of Active Namenode>:50070
It will show whether the name node is Active or on standby.
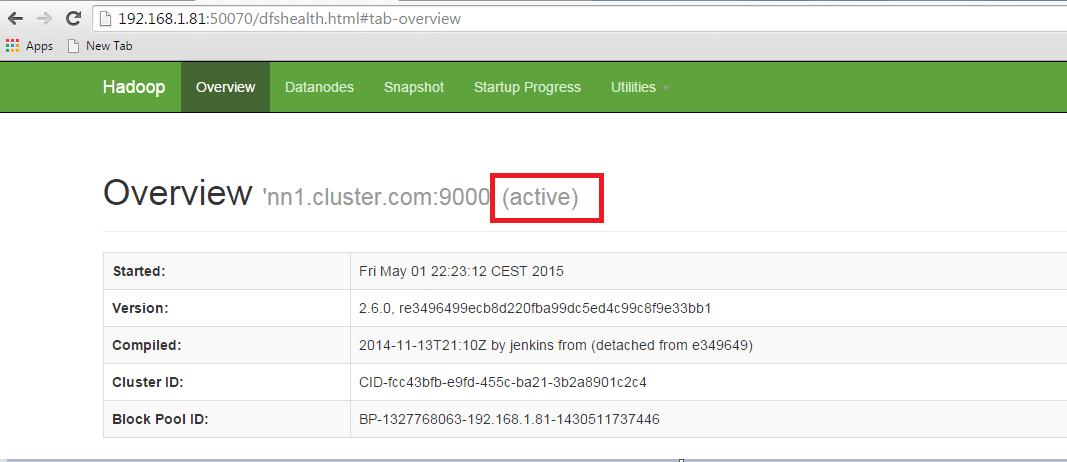
Open another name node details using the web browser.
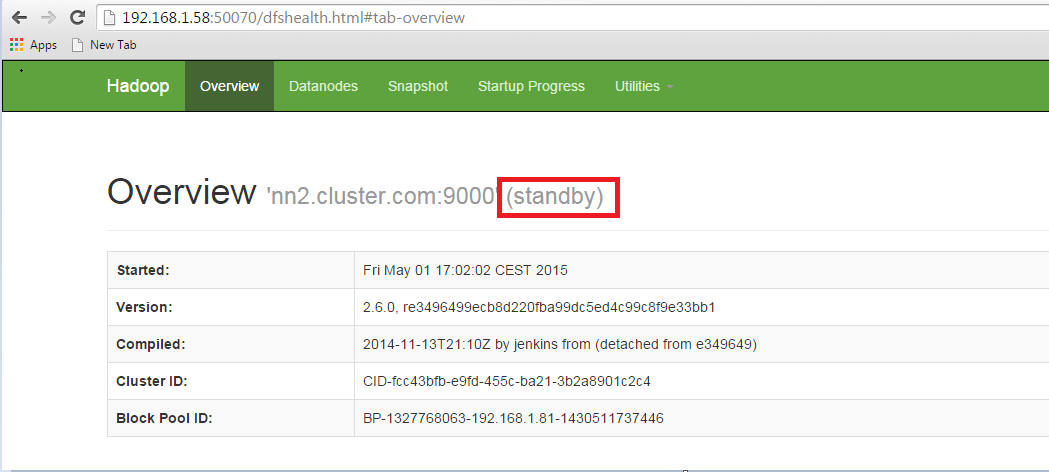
In the Active namenode, kill the namenode daemon to change the Standby name node to active namenode.
Enter jps in Active namenode and kill the daemon.
Command: sudo kill -9 <namenode process ID>
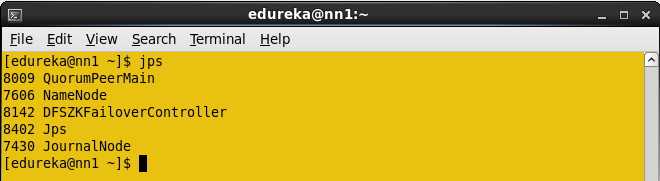
The Namenode process ID is 7606, kill the namenode.
Command : Sudo kill -9 7606

Open the two nodes through web browser and check the status.
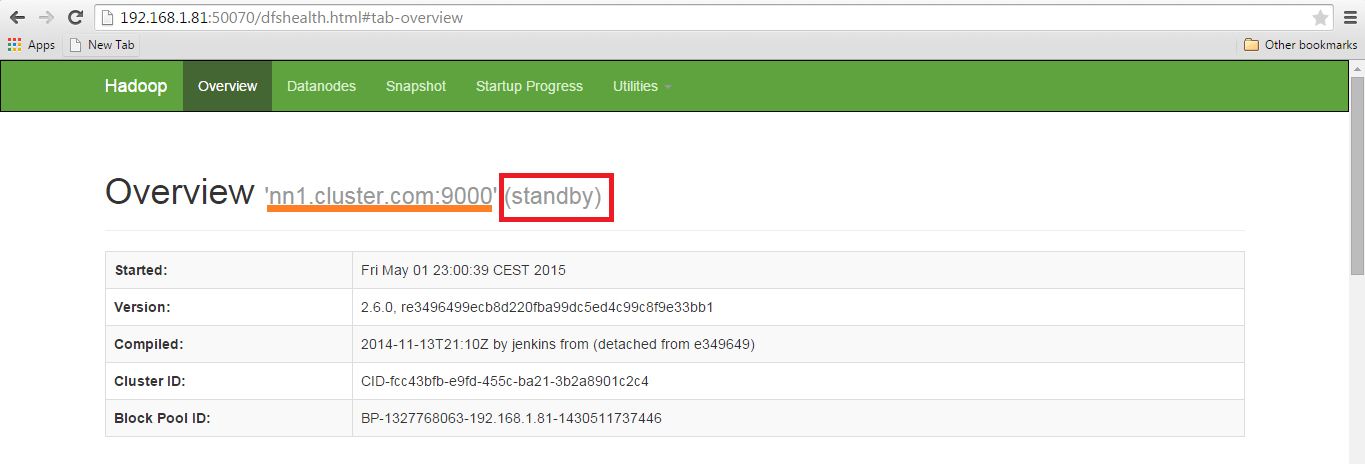
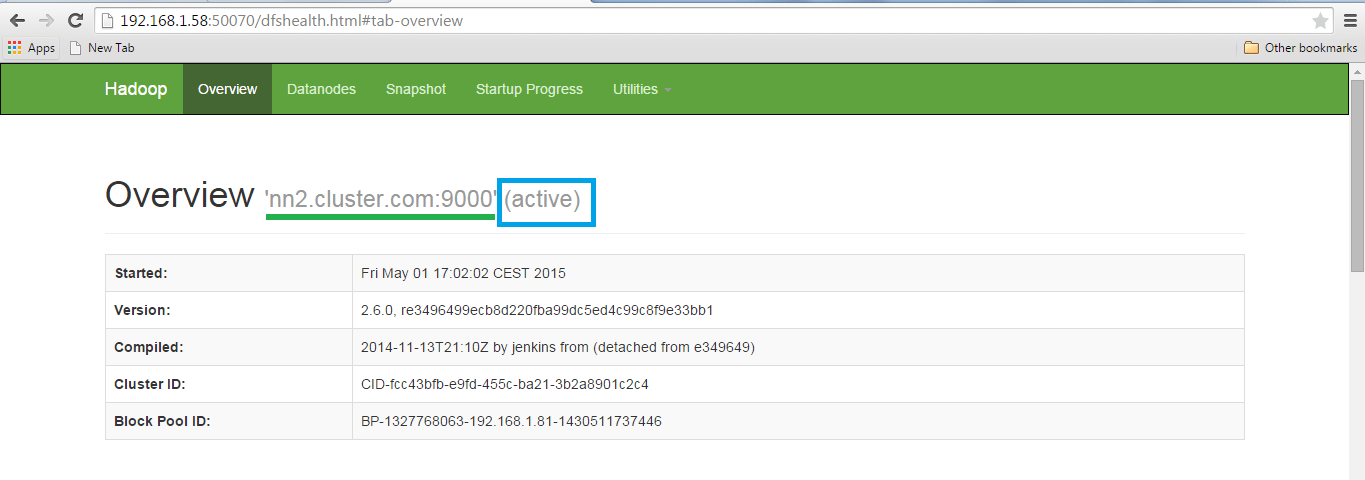
NameNode status.
Congratulations, you have successfully setup a HDFS High Availability Cluster in Hadoop.
Now that you have understood Hadoop High Availability Cluster Architecture, check out the Big Data course in Pune by Edureka, a trusted online learning company with a network of more than 250,000 satisfied learners spread across the globe. The Edureka’s Big Data Architect Course helps learners become expert in HDFS, Yarn, MapReduce, Pig, Hive, HBase, Oozie, Flume and Sqoop using real-time use cases on Retail, Social Media, Aviation, Tourism, Finance domain.
Got a question for us? Please mention it in the comments section and we will get back to you.
window._LQ_ = window._LQ_ || {};
lqQuizModal(window, document, {quizId:’XAIVp8′,baseUrl:’https://quiz.leadquizzes.com/’,trigger:’exit’}, _LQ_);
| Course Name | Date | |
|---|---|---|
| Big Data Hadoop Certification Training Course | Class Starts on 11th February,2023 11th February SAT&SUN (Weekend Batch) | View Details |
| Big Data Hadoop Certification Training Course | Class Starts on 8th April,2023 8th April SAT&SUN (Weekend Batch) | View Details |







































 REGISTER FOR FREE WEBINAR
REGISTER FOR FREE WEBINAR  Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP










Normally a client would send a get/put file request to a particular “namenode” right? So once a failover has happened how would client get to know about it?
Assuming it is client responsibility to perform the retry on failure in that case is there a way client can first query for currently active namenode and then send a request to that one?
It would be really good to show how to restart this system.
Thank you for sharing this valuable information.
Thank you @Baris for appreciating our work. We will look into your suggestions as well. Cheers :)
my hadoop cluster is setup, and working fine:
i ran word count example:
can anybody provide me the following formulas to calculate some parameters:
Response Time:
Throughput:
Average I/o Rate:
Execution Time:
Thanks in advance
Hello. Its a very helpful instruction for me!
Do we need to format the ZKFC on Standby NameNode too?
According to this page: http://hadoop.apache.org/docs/r2.7.3/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabilityWithQJM.html#Initializing_HA_state_in_ZooKeeper we must do it one time: “…next step is to initialize required state in ZooKeeper. You can do so by running the following command from one of the NameNode hosts.”
Wow, It is a very helpful information. Thank you so much.
sap hana online training in usa
Normally when we setup a hadoop cluster (non HA), we need to configure yarn by modifying its yarn-site.xml . For HA, don’t we require any HA specific modification to yarn-site.xml ?
Thanks Sanjay for going through the blog.
In this blog, we are modifying hdfs-site.xml because we are enabling HA feature only for NameNode. And yes you are absolutely correct, you can have HA for ResourceManager as well where you will have to modify the yarn-site.xml similarly. You can follow the Hadoop documentations to setup HA for ResouceManager which is given below:
https://hadoop.apache.org/docs/r2.7.2/hadoop-yarn/hadoop-yarn-site/ResourceManagerHA.html
I am just correcting your HA Architecture image
After killing active or standby namenode I am not getting web view of killing namenode. Is it possible to getting web view after killing namenode ?. But you have seen two namenode web view after killing one namenode. How it is possible? I am facing some problem in my namenode.
Thank you
Rakib
Hey Rakib,
If the namenode is manualy transitioned from active to standby you should be able to see the WEB UI of the namenode as it is still active. But if there is a failover in the active namenode and the it got a automatic transition to the standby namenode you can’t have the web ui because of the obvious reason that the namenode is down. Once you fix the dead namenode you can see the UI with STANDBY mentioned in the UI. Hope this helps
Thanks,
MK
Hey Rakibul, thanks for checking out the blog. Please follow the steps given below:
-> Please Check your hdfs-site.xml configuration file and make sure that you have set up the automatic failover as per given in the blog.
-> In case you are still facing the issue, change the directory for namenode, datanode, JN and zookeeper and give the permission 755 for these directories
chmod 755 directory_path
-> Format the Active Namenode and start the services as per given in the blog
Hope this helps.
am inistaling high avalability like nn1 & nn2 and dn1 …. in that nn1 and nn2 both are standby mode only what i do now
Hope you got the solution by now anil. It might be the reason that you did not enable automatic failover property in hdfs-site.xml. According to what you are saying that your cluster is in manual failover mode. In this scenario you have to individually designate which name node should be active or standby.
hdfs haadmin -transitionToActive nn1
(nn1 – Active , nn2 – Standby)
hdfs haadmin -transitionToStandby nn1
(nn1 – Standby , nn2 – Standby)
hdfs haadmin -transitionToActive nn2
(nn1 – Standby , nn2 – Active)
hdfs haadmin -transitionToStandby nn2
(nn1 – Standby , nn2 – Standby)
Check your name node service status using the command:
hdfs haadmin -getServiceStatus
If you by mistake make both of them active you might encounter scenario of split-brain where on both nodes edits will be in progress resulting in corrupted metadata.
Hope this helps!
Thanks,
MK
Getting below error when i follow the above configuration settings.
15/11/08 01:58:34 ERROR namenode.FSNamesystem: FSNamesystem initialization failed.
java.io.IOException: Invalid configuration: a shared edits dir must not be specified if HA is not enabled.
and i dont find solution for this from google.
Can someone help
regards
suresh bk
Hi Suresh bk
Thank you for reaching out to us.
You can connect with our 24/7 support team with all your queries and doubts regarding Hadoop once you enroll for the course.
You can also get in touch with us by contacting our sales team on +91-8880862004 (India) or 1800 275 9730 (US toll free). You can mail us on [email protected].