






Azure Data Engineer Associate Certification C ...
- 2k Enrolled Learners
- Weekend
- Live Class
(550)
Looking out for Hadoop Cluster Interview Questions that are frequently asked by employers? Here is the second list of Hadoop Cluster Interview Questions which covers setting up a Hadoop Cluster. I hope you must not have missed the first part of our Hadoop Interview Questions series which covers the top 50 Hadoop interview questions.
Always keep in mind that, only theoretical knowledge is not enough to crack an interview. Employers expects from the candidate to have practical knowledge and hands-on experience on Hadoop as well. So, this Hadoop Cluster Interview Questions will help you to gain practical knowledge of Hadoop framework.
If you are interested in installing Hadoop Cluster on your own system, you can go through our blog on Single Node Hadoop Cluster Setup and Multi node Hadoop Cluster setup.
We have three modes in which Hadoop can run and that are:
| Modes | Description |
| Standalone (local) |
|
| Pseudo-distributed |
|
| Fully distributed |
|
Pseudo mode is used in both for development and in the testing environment. In the Pseudo mode, all the daemons run on the same machine.
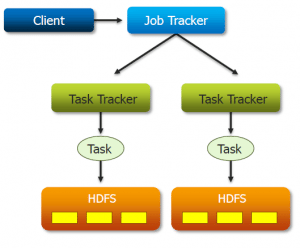
This is an important question as Fully Distributed mode is used in the production environment, where we have ‘n’ number of machines forming a Hadoop cluster. Hadoop daemons run on a cluster of machines. There is one host onto which Namenode is running and other hosts on which Datanodes are running. NodeManagers are installed on every DataNode and it is responsible for execution of the task on every single DataNode. All these NodeManagers are managed by ResourceManager, which receives the processing requests, and then passes the parts of requests to corresponding NodeManagers accordingly.
This is a technical question which challenges your basic concept. /etc/hosts file contains the hostname and their IP address of that host. It maps the IP address to the hostname. In Hadoop cluster, we store all the hostnames (master and slaves) with their IP addresses in /etc/hosts so, that we can use hostnames easily instead of IP addresses.
You are expected to remember basic server port numbers if you are working with Hadoop. The port number for corresponding daemons are as follows:
Namenode – ’50070’
ResourceManager – ’8088’
MapReduce JobHistory Server – ’19888’.
♣ Tip: Generally, approach this question by telling the 4 main configuration files in Hadoop and giving their brief descriptions to show your expertise.
These files are in the conf/hadoop/ directory inside Hadoop directory.
♣ Tip: To check your knowledge on Hadoop the interviewer may ask you this question.
CLASSPATH includes all the directories containing jar files required to start/stop Hadoop daemons. The CLASSPATH is set inside /etc/hadoop/hadoop-env.sh file.
♣ Tip: This is a theoretical question, but if you add a practical taste to it, you might get a preference.
The map output is stored in an in-memory buffer; when this buffer is almost full, then spilling phase starts in order to move data to a temp folder.
Map output is first written to buffer and buffer size is decided by mapreduce.task.io.sort.mb property .By default, it will be 100 MB.
When the buffer reaches certain threshold, it will start spilling buffer data to disk. This threshold is specified in mapreduce.map.sort.spill.percent .
This is an easy question, tar -xvf /file_location/filename.tar.gz command will extract the tar.gz compressed file.
By using the following commands we can check whether Java and Hadoop are installed and their paths are set inside .bashrc file:
For checking Java – java -version
For checking Hadoop – hadoop version
The default replication factor is 3.
♣ Tip: Default Replication Factor could be changed in three ways. Answering all the three ways will show your expertise.
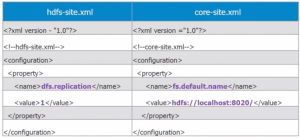
<property> <name>dfs.replication</name> <value>5</value> <description>Block Replication</description> </property>
hadoop fs –setrep –w 3 /file_location
hadoop fs –setrep –w 3 -R /directory_location
The full form of fsck is File System Check. HDFS supports the fsck (filesystem check) command to check for various inconsistencies. It is designed for reporting the problems with the files in HDFS, for example, missing blocks of a file or under-replicated blocks.
The three main hdfs-site.xml properties are:
If you get a ‘connection refused java exception’ when you type hadoop fsck, it could mean that the NameNode is not working on your VM.
We can view compressed files in HDFS using hadoop fs -text /filename command.
♣ Tip: Approach this question by first explaining safe mode and then moving on to the commands.
Safe Mode in Hadoop is a maintenance state of the NameNode during which NameNode doesn’t allow any changes to the file system. During Safe Mode, HDFS cluster is read-only and doesn’t replicate or delete blocks.
jps command is used to check all the Hadoop daemons like NameNode, DataNode, ResourceManager, NodeManager etc. which are running on the machine.
This question has two answers, answering both will give you a plus point. We can restart NameNode by following methods:
To check whether NameNode is working or not, use the jps command, this will show all the running Hadoop daemons and there you can check whether NameNode daemon is running or not.
If you want to look for NameNode in the browser, the port number for NameNode web browser UI is 50070. We can check in web browser using http://master:50070/dfshealth.jsp.
♣ Tip: Explain all the three ways of stopping and starting Hadoop daemons, this will show your expertise.
./sbin/hadoop-daemon.sh start namenode
./sbin/hadoop-daemon.sh start datanode
./sbin/yarn-daemon.sh start resourcemanager
./sbin/yarn-daemon.sh start nodemanager
./sbin/mr-jobhistory-daemon.sh start historyserver
and stop them similarly.
Slaves file consists of a list of hosts, one per line and the list contains DataNode location on which Node Manager servers run.
The masters file contains Secondary NameNode server location.
hadoop-env.sh provides the environment for Hadoop to run. For example, JAVA_HOME, CLASSPATH etc. are set over here.
As we discussed earlier, where all the configuration files reside, thus hadoop-env.sh file is present in the /etc/hadoop directory.
PID stands for ‘Process ID’. This directory stores the Process ID of the servers that are running.
♣ Tip: As this file is configured manually only in special cases, so answering this question will impress the interviewer indicating your expertise about configuration files.
hadoop-metrics.properties is used for ‘Performance Reporting‘ purposes. It controls the reporting for Hadoop. The API is abstract so that it can be implemented on top of a variety of metrics client libraries. The choice of client library is a configuration option, and different modules within the same application can use different metrics implementation libraries. This file is stored inside /etc/hadoop.
You should answer this question as, the Hadoop core uses Shell (SSH) for communication with salve and to launch the server processes on the slave nodes. It requires a password-less SSH connection between the master and all the slaves and the secondary machines, so every time it does not have to ask for authentication as master and slave requires rigorous communication.
We need a password-less SSH in a Fully-Distributed environment because when the cluster is live and running in Fully Distributed environment, the communication is too frequent. The DataNode and the NodeManager should be able to send messages quickly to master server.
No, not at all. Hadoop cluster is an isolated cluster and generally, it has nothing to do with the internet. It has a different kind of a configuration. We needn’t worry about that kind of a security breach, for instance, someone hacking through the internet, and so on. Hadoop has a very secured way to connect to other machines to fetch and to process data.
SSH works on Port No. 22, though it can be configured. 22 is the default Port number.
SSH is nothing but a secure shell communication, it is a kind of a protocol that works on a Port No. 22, and when you do an SSH, what you really require is a password, to connect to the other machine. SSH is not only between masters and slaves, but can be between two hosts.
When a ResourceManager is down, it will not be functional (for submitting jobs) but NameNode will be present. So, the cluster is accessible if NameNode is working, even if the ResourceManager is not working.
♣ Tip: Attempt this question by starting with the command to format the HDFS and then exlain what this command does.
Hadoop distributed file system(HDFS) can be formatted using bin/hadoop namenode -format command. This command formats the HDFS via NameNode. This command is only executed for the first time. Formatting the file system means initializing the directory specified by the dfs.name.dir variable. If you run this command on existing filesystem, you will lose all your data stored on your NameNode. Formatting a Namenode will not format the DataNode. It will format the FsImage and edit logs data stored on the NameNode and will lose the data about the location of blocks stored in HDFS.Get a better understanding of HDFS from this Big Data Course.
Never format, up and running Hadoop filesystem. You will lose all your data stored in the HDFS.
Red Hat Linux and Ubuntu are the best Operating Systems for Hadoop. Windows is not used frequently for installing Hadoop as there are many support problems attached with Windows. Thus, Windows is not a preferred environment for Hadoop.
I hope these Hadoop Cluster Interview Questions were helpful for you. This is just a beginning of our Hadoop Interview Question series. I would suggest you to go through the whole series, to get in-depth knowledge on Hadoop Interview Questions. It’s never too late to strengthen your basics. Learn Hadoop from industry experts while working with real-life use cases.
Got a question for us? Please mention them in the comments section and we will get back to you.
| Course Name | Date | |
|---|---|---|
| Big Data Hadoop Certification Training Course | Class Starts on 11th February,2023 11th February SAT&SUN (Weekend Batch) | View Details |
| Big Data Hadoop Certification Training Course | Class Starts on 8th April,2023 8th April SAT&SUN (Weekend Batch) | View Details |




































 REGISTER FOR FREE WEBINAR
REGISTER FOR FREE WEBINAR  Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP










Hi Support team , Please update questions and answers for Hadoop 2.0 as well.
please update the question for Hadoop 2.0 also… some of the questions are specific to Hadoop 1.0 – where Task tracker and Job trackers are mentioned ….
Hi Awadhesh, thanks for commenting. We will take your suggestion in to consideration.
Hi Edureka Support,
I still see that the same version 1 materials are being included in the LMS for the version 2 classes. It will be helpful and much appreciated if you could update the LMS with hadoop version 2 materials.
I have just on track a web site, the info you provide resting on this web position has helped me tremendously. Thankfulness for all of your time & work. “A physicist is an atom’s way of knowing concerning atoms.” by George Wald.
lol Java are pretty awesome, irritating up to methods many updates they’ve although cool items!