








AWS has been rated a Leader in the 2022 Magic Quadrant for Cloud Infrastructure and Platform Services for the twelfth time in a row (CIPS). AWS is the longest-running CIPS Magic Quadrant Leader, according to Gartner. 48% of enterprises plan to keep spending steadily on cloud, according to IDC research. Undoubtedly, the AWS Solution Architect position is one of the most sought after amongst IT jobs. You, too, can maximize the Cloud computing career opportunities that are sure to come your way by taking AWS Certification training with Edureka. In this blog, we are here to set you up for your next interview with AWS Interview Questions and Answers

Why AWS Interview Questions?
The AWS Solution Architect Role: With regards to AWS, a Solution Architect would design and define AWS architecture for existing systems, migrating them to cloud architectures as well as developing technical road-maps for future AWS cloud implementations. So, through this AWS interview questions and answers article, I will bring you top and frequently asked AWS interview questions. Gain proficiency in designing, planning, and scaling cloud implementation with the AWS Masters Program.
The following is the outline of this article:
- Section 1: Basics AWS Interview Questions
- Section 2: Amazon EC2 Interview Questions
- Section 3: Amazon Storage Interview Questions
- Section 4: AWS VPC Interview Questions
- Section 5: Amazon Database Interview Questions
- Section 6: AWS Auto Scaling, AWS Load Balancer Interview Questions
- Section 7: CloudTrail, Route 53 Interview Questions
- Section 8: AWS SQS, AWS SNS, AWS SES, AWS ElasticBeanstalk Interview Questions
- Section 9: AWS OpsWorks, AWS KMS Interview Questions
Now in every section, we will start with AWS basic interview questions, and then move towards AWS interview questions and answers for experienced people which are more technically challenging,
AWS Interview Questions And Answers 2023 | AWS Solution Architect Training | Edureka

Section 1: Basic AWS Interview Questions
1. What is Cloud Computing? Can you talk about and compare any two popular Cloud Service Providers?
For a detailed discussion on this topic, please refer our Cloud Computing blog. Following is the comparison between two of the most popular Cloud Service Providers:
Amazon Web Services Vs Microsoft Azure
| Parameters | AWS | Azure |
| Initiation | 2006 | 2010 |
| Market Share | 4x | x |
| Implementation | Less Options | More Experimentation Possible |
| Features | Widest Range Of Options | Good Range Of Options |
| App Hosting | AWS not as good as Azure | Azure Is Better |
| Development | Varied & Great Features | Varied & Great Features |
| IaaS Offerings | Good Market Hold | Better Offerings than AWS |
2.. Try this AWS scenario based interview question. I have some private servers on my premises, also I have distributed some of my workload on the public cloud, what is this architecture called?
- Virtual Private Network
- Private Cloud
- Virtual Private Cloud
- Hybrid Cloud
Answer D.
Explanation: This type of architecture would be a hybrid cloud. Why? Because we are using both, the public cloud, and your on premises servers i.e the private cloud. To make this hybrid architecture easy to use, wouldn’t it be better if your private and public cloud were all on the same network(virtually). This is established by including your public cloud servers in a virtual private cloud, and connecting this virtual cloud with your on premise servers using a VPN(Virtual Private Network).
Learn to design, develop, and manage a robust, secure, and highly available cloud-based solution for your organization’s needs with the Google Cloud Platform Course.
3. Define and explain the three initial orders of all services and the AWS products erected on them.
There are three primary types of cloud services: computing, storage, and networking.
Then there are AWS products built based on the three orders of all services. Computing services such as EC2, Elastic Beanstalk, Lambda, Auto-Scaling, and Lightsail are exemplifications. S3, Glacier, Elastic Block Storage, and the Elastic File System exemplify the storage. VPC, Amazon CloudFront, and Route53 are exemplifications of networking services.
4. What are the main features of Cloud Computing?
Cloud computing has the following key characteristics:
- Massive amounts of computing resources can be provisioned quickly.
- Resources can be accessed from any location with an internet connection due to its location independence.
- Unlike physical devices, cloud storage has no capacity constraints which makes it very efficient for storage.
- Multi-Tenancy allows a large number of users to share resources.
- Data backup and disaster recovery are becoming easier and less expensive with cloud computing.
- Its Scalability enables businesses to scale up and scale down as needed with cloud computing.
5. Explain AWS.
AWS is an abbreviation for Amazon Web Services, which is a collection of remote computing services also known as Cloud Computing. This technology is also known as IaaS, or Infrastructure as a Service.
6. Name some of the non-regional AWS services.
Some of the non-regional AWS services.
- CloudFront
- IAM
- Route 53
- Web Application Firewall
7. What are the different layers that define cloud architecture?
The following are the various layers operated by cloud architecture:
- CLC or Cloud Controller.
- Cluster Controller
- SC or Storage Controller
- NC, or Node Controller
- Walrus
8. What are the various layers of cloud computing? Explain their work.
Cloud computing categories have various layers that include
- Infrastructure as a Service (IaaS) is the on-demand provision of services such as servers, storage, networks, and operating systems.
- Platform as a Service (PaaS) combines IaaS with an abstracted collection of middleware services, software development, and deployment tools.
- PaaS also enables developers to create web or mobile apps in the cloud quickly.
- Software as a Service (SaaS) is a software application that has been delivered on-demand, in a multi-tenant model
- Function as a Service (FaaS) enables end users to build and execute app functionalities on a serverless architecture.
9. What are the various Cloud versions?
There are several models for deploying cloud services:
- The public cloud is a collection of computer resources such as hardware, software, servers, storage, and so on that are owned and operated by third-party cloud providers for use by businesses or individuals.
- A private cloud is a collection of resources owned and managed by an organization for use by its employees, partners, or customers.
- A hybrid cloud is one that combines public and private cloud services.
10. List the pros and cons of serverless computing.
Advantages:
- Cost-effective
- Operations have been simplified.
- Improves Productivity
- Scalable
Disadvantages:
- This can result in response latency
- Due to resource constraints, it is not suitable for high-computing operations.
- Not very safe.
- Debugging can be difficult.
11. What characteristics distinguish cloud architecture from traditional cloud architecture?
The characteristics are as follows:
- In the cloud, hardware requirements are met based on the demand generated by cloud architecture.
- When there is a demand for resources, cloud architecture can scale them up.
- Cloud architecture can manage and handle dynamic workloads without a single point of failure.
12. What are the featured services of AWS?
AWS’s key components are as follows:
- Elastic compute cloud (EC2): It is a computing resource that is available on demand for hosting applications. In times of uncertain workloads, EC2 comes in handy.
- Route 53: It is a web-based DNS service.
- Simple Storage Device S3: This is a storage device service that is widely used in AWS Identity and Access Management.
- Elastic Block Store: It allows you to store constant volumes of data and is integrated with EC2. It also allows you to persist data.
- Cloud watch: It allows you to monitor the critical areas of AWS and even set a reminder for troubleshooting.
- Simple Email Service: It allows you to send emails using regular SMTP or a restful API call.
Section 2: AWS Interview Questions and Answers for Amazon EC2
For a detailed discussion on this topic, please refer to our EC2 AWS blog.
13. What does the following command do with respect to the Amazon EC2 security groups?
ec2-create-group CreateSecurityGroup
- Groups the user created security groups into a new group for easy access.
- Creates a new security group for use with your account.
- Creates a new group inside the security group.
- Creates a new rule inside the security group.
Answer B.
Explanation: A Security group is just like a firewall, it controls the traffic in and out of your instance. In AWS terms, the inbound and outbound traffic. The command mentioned is pretty straight forward, it says create security group, and does the same. Moving along, once your security group is created, you can add different rules in it. For example, you have an RDS instance, to access it, you have to add the public IP address of the machine from which you want to access the instance in its security group.
14. Here is aws scenario based interview question. You have a video trans-coding application. The videos are processed according to a queue. If the processing of a video is interrupted in one instance, it is resumed in another instance. Currently there is a huge back-log of videos which needs to be processed, for this you need to add more instances, but you need these instances only until your backlog is reduced. Which of these would be an efficient way to do it?
You should be using an On Demand instance for the same. Why? First of all, the workload has to be processed now, meaning it is urgent, secondly you don’t need them once your backlog is cleared, therefore Reserved Instance is out of the picture, and since the work is urgent, you cannot stop the work on your instance just because the spot price spiked, therefore Spot Instances shall also not be used. Hence On-Demand instances shall be the right choice in this case.
15. You have a distributed application that periodically processes large volumes of data across multiple Amazon EC2 Instances. The application is designed to recover gracefully from Amazon EC2 instance failures. You are required to accomplish this task in the most cost effective way.
Which of the following will meet your requirements?
- Spot Instances
- Reserved instances
- Dedicated instances
- On-Demand instances
Answer: A
Explanation: Since the work we are addressing here is not continuous, a reserved instance shall be idle at times, same goes with On Demand instances. Also it does not make sense to launch an On Demand instance whenever work comes up, since it is expensive. Hence Spot Instances will be the right fit because of their low rates and no long term commitments.
Check out our AWS Certification Training in Top Cities
For a detailed, You can even check out the details of Migrating to AWS with the AWS Cloud Migration Training.
16. How is stopping and terminating an instance different from each other?
Starting, stopping and terminating are the three states in an EC2 instance, let’s discuss them in detail:
- Stopping and Starting an instance: When an instance is stopped, the instance performs a normal shutdown and then transitions to a stopped state. All of its Amazon EBS volumes remain attached, and you can start the instance again at a later time. You are not charged for additional instance hours while the instance is in a stopped state.
- Terminating an instance: When an instance is terminated, the instance performs a normal shutdown, then the attached Amazon EBS volumes are deleted unless the volume’s deleteOnTermination attribute is set to false. The instance itself is also deleted, and you can’t start the instance again at a later time.
17. If I want my instance to run on a single-tenant hardware, which value do I have to set the instance’s tenancy attribute to?
- Dedicated
- Isolated
- One
- Reserved
Answer A.
Explanation: The Instance tenancy attribute should be set to Dedicated Instance. The rest of the values are invalid.
18. When will you incur costs with an Elastic IP address (EIP)?
- When an EIP is allocated.
- When it is allocated and associated with a running instance.
- When it is allocated and associated with a stopped instance.
- Costs are incurred regardless of whether the EIP is associated with a running instance.
Answer C.
Explanation: You are not charged, if only one Elastic IP address is attached with your running instance. But you do get charged in the following conditions:
- When you use more than one Elastic IPs with your instance.
- When your Elastic IP is attached to a stopped instance.
- When your Elastic IP is not attached to any instance.
19. How is a Spot instance different from an On-Demand instance or Reserved Instance?
First of all, let’s understand that Spot Instance, On-Demand instance and Reserved Instances are all models for pricing. Moving along, spot instances provide the ability for customers to purchase compute capacity with no upfront commitment, at hourly rates usually lower than the On-Demand rate in each region. Spot instances are just like bidding, the bidding price is called Spot Price. The Spot Price fluctuates based on supply and demand for instances, but customers will never pay more than the maximum price they have specified. If the Spot Price moves higher than a customer’s maximum price, the customer’s EC2 instance will be shut down automatically. But the reverse is not true, if the Spot prices come down again, your EC2 instance will not be launched automatically, one has to do that manually. In Spot and On demand instance, there is no commitment for the duration from the user side, however in reserved instances one has to stick to the time period that he has chosen.
20. Are the Reserved Instances available for Multi-AZ Deployments?
- Multi-AZ Deployments are only available for Cluster Compute instances types
- Available for all instance types
- Only available for M3 instance types
- D. Not Available for Reserved Instances
Answer B.
Explanation: Reserved Instances is a pricing model, which is available for all instance types in EC2.
21. How to use the processor state control feature available on the c4.8xlarge instance?
The processor state control consists of 2 states:
- The C state – Sleep state varying from c0 to c6. C6 being the deepest sleep state for a processor
- The P state – Performance state p0 being the highest and p15 being the lowest possible frequency.
Now, why the C state and P state. Processors have cores, these cores need thermal headroom to boost their performance. Now since all the cores are on the processor the temperature should be kept at an optimal state so that all the cores can perform at the highest performance.
Now how will these states help in that? If a core is put into sleep state it will reduce the overall temperature of the processor and hence other cores can perform better. Now the same can be synchronized with other cores, so that the processor can boost as many cores it can by timely putting other cores to sleep, and thus get an overall performance boost.
Concluding, the C and P state can be customized in some EC2 instances like the c4.8xlarge instance and thus you can customize the processor according to your workload.
22. What kind of network performance parameters can you expect when you launch instances in cluster placement group?
The network performance depends on the instance type and network performance specification, if launched in a placement group you can expect up to
- 10 Gbps in a single-flow,
- 20 Gbps in multiflow i.e full duplex
- Network traffic outside the placement group will be limited to 5 Gbps(full duplex).
23. To deploy a 4 node cluster of Hadoop in AWS which instance type can be used?
First let’s understand what actually happens in a Hadoop cluster, the Hadoop cluster follows a master slave concept. The master machine processes all the data, slave machines store the data and act as data nodes. Since all the storage happens at the slave, a higher capacity hard disk would be recommended and since master does all the processing, a higher RAM and a much better CPU is required. Therefore, you can select the configuration of your machine depending on your workload. For e.g. – In this case c4.8xlarge will be preferred for master machine whereas for slave machine we can select i2.large instance. If you don’t want to deal with configuring your instance and installing hadoop cluster manually, you can straight away launch an Amazon EMR (Elastic Map Reduce) instance which automatically configures the servers for you. You dump your data to be processed in S3, EMR picks it from there, processes it, and dumps it back into S3.
24. Where do you think an AMI fits, when you are designing an architecture for a solution?
AMIs(Amazon Machine Images) are like templates of virtual machines and an instance is derived from an AMI. AWS offers pre-baked AMIs which you can choose while you are launching an instance, some AMIs are not free, therefore can be bought from the AWS Marketplace. You can also choose to create your own custom AMI which would help you save space on AWS. For example if you don’t need a set of software on your installation, you can customize your AMI to do that. This makes it cost efficient, since you are removing the unwanted things.
25. How do you choose an Availability Zone?
Let’s understand this through an example, consider there’s a company which has user base in India as well as in the US.
Let us see how we will choose the region for this use case :


So concluding, North Virginia should be chosen for this use case.
26. Is one Elastic IP address enough for every instance that I have running?
Depends! Every instance comes with its own private and public address. The private address is associated exclusively with the instance and is returned to Amazon EC2 only when it is stopped or terminated. Similarly, the public address is associated exclusively with the instance until it is stopped or terminated. However, this can be replaced by the Elastic IP address, which stays with the instance as long as the user doesn’t manually detach it. But what if you are hosting multiple websites on your EC2 server, in that case you may require more than one Elastic IP address.
27. What are the best practices for Security in Amazon EC2?
There are several best practices to secure Amazon EC2. A few of them are given below:
- Use AWS Identity and Access Management (IAM) to control access to your AWS resources.
- Restrict access by only allowing trusted hosts or networks to access ports on your instance.
- Review the rules in your security groups regularly, and ensure that you apply the principle of least
- Privilege – only open up permissions that you require.
- Disable password-based logins for instances launched from your AMI. Passwords can be found or cracked, and are a security risk.
28. How can you upgrade or downgrade a system with little to no downtime?
The following steps can be used to update or downgrade a system with near-zero downtime:
First, you will have to Launch the EC2 console, then secondly, select the AMI Operating System. The next step is creating an instance using the new instance type; you need to install the updates and go to set up apps. Then check to determine if the instances are operational or not, and if everything is well, you will deploy the new instance and replace all the old ones. Now once everything is ready for installation, you can upgrade or downgrade the system with very little to no downtime
29. What’s the Amazon EC2 root device volume?
The image used to boot an EC2 instance is saved on the root device slice, which happens when an Amazon AMI launches a new EC2 case. This root device volume is supported by EBS or an instance store. In general, the lifetime of an EC2 instance does not affect the root device data stored on Amazon EBS.
30. Mention and explain the many types of Amazon EC2 instances.
The various instances available on Amazon EC2 General-purpose Instances:
- They are used to compute a wide range of tasks and aid in allocating processor, memory, and networking resources.
- Instances optimized for computing: These are suitable for compute-intensive workloads. They can handle batch processing workloads, high-performance web servers, machine learning inference, and a wide range of other tasks.
- Memory-optimized: They process and provide tasks that manage massive datasets in memory.
- Computing speed: It accelerates the execution of floating-point number calculations, data pattern matching, and graphics processing.
- Optimized Storage: They conduct operations on local storage that need sequential read and write access to big data sets.
31. What exactly do you mean by ‘changing’ in Amazon EC2?
Amazon EC2 now provides the option for customers to move from the current ‘instance count-based constraints’ to the new ‘vCPU Based restrictions.’ As a result, when launching a demand-driven mix of instance types, usage is assessed in terms of the number of vCPUs.
32. Your application is running on an EC2 instance. When your instance’s CPU consumption reaches 80%, you must lower the load on it. What method do you employ to finish the task?
Setting up an autoscaling group to deploy new instances when an EC2 instance’s CPU consumption exceeds 80% and distributing traffic among instances via the deployment of an application load balancer and the designation of EC2 instances as target instances can do this.
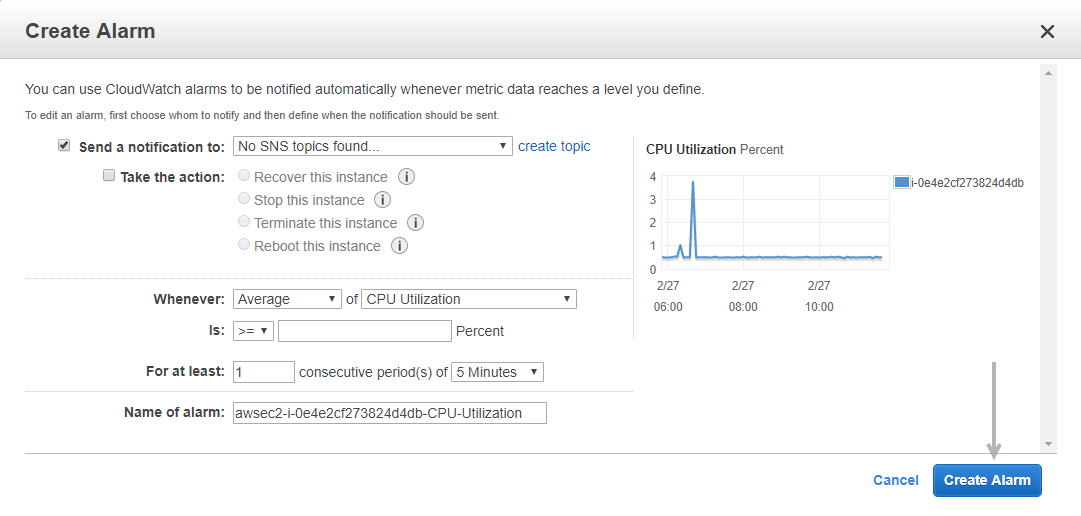
33. How does one set up CloudWatch to recover an EC2 instance?
Here’s how you can set them up:
- Using Amazon CloudWatch, create an alarm.
- Navigate to the Define Alarm -> Actions tab of the Alarm.
- Choose the Option to Recover This Instance

If you have lost your key, follow the procedures below to recover an EC2 instance:
Step 1. Verify that the EC2Config service is operating.
Step 2. Detach the instance’s root volume.
Step 3. Connect the volume to a temporary instance
Step 4. Change the configuration file
Step 5. Restart the original instance.
Section 3: AWS interview questions for Amazon Storage
35. What exactly is Amazon S3?
Explanation S3 stands for Simple Storage Service, and Amazon S3 is the most extensively used storehouse platform. S3 is an object storehouse service that can store and recoup any volume of data from any position. Despite its rigidity, it’s basically measureless as well as cost-effective because it’s on- a demand storehouse. Away from these advantages, it provides new situations of continuity and vacuity. Amazon S3 aids in data operation for cost reduction, access control, and compliance.
36. What Storage Classes are available in Amazon S3?
Explanation: The following Storage Classes are accessible using Amazon S3:
- Storage class Amazon S3 Glacier Instant Retrieval
- Amazon S3 Glacier Flexible Retrieval Storage Class (Formerly S3 Glacier)
- Glacier Deep Archive on Amazon S3 (S3 Glacier Deep Archive)
- Storage class S3 Outposts
- Amazon S3 Standard-Occasional Access (S3 Standard-IA)
- Amazon S3 One Zone-Only Occasional Access (S3 One Zone-IA)
- Amazon S3 Basic (S3 Standard)
- Amazon S3 Storage with Reduced Redundancy
- Intelligent-Tiering on Amazon S3 (S3 Intelligent-Tiering)
37. How do you auto-delete old snapshots?
Explanation: Here’s how to delete outdated photos automatically:
- Take snapshots of the EBS volumes on Amazon S3 in accordance with process and best practices.
- To manage all of the snapshots automatically, use AWS Ops Automator.
- You may use this to generate, copy, and remove Amazon EBS snapshots.
38. Another scenario based interview question. You need to configure an Amazon S3 bucket to serve static assets for your public-facing web application. Which method will ensure that all objects uploaded to the bucket are set to public read?
- Set permissions on the object to public read during upload.
- Configure the bucket policy to set all objects to public read.
- Use AWS Identity and Access Management roles to set the bucket to public read.
- Amazon S3 objects default to public read, so no action is needed.
Answer B.
Explanation: Rather than making changes to every object, its better to set the policy for the whole bucket. IAM is used to give more granular permissions, since this is a website, all objects would be public by default.
39. A customer wants to leverage Amazon Simple Storage Service (S3) and Amazon Glacier as part of their backup and archive infrastructure. The customer plans to use third-party software to support this integration. Which approach will limit the access of the third party software to only the Amazon S3 bucket named “company-backup”?
- A custom bucket policy limited to the Amazon S3 API in three Amazon Glacier archive “company-backup”
- A custom bucket policy limited to the Amazon S3 API in “company-backup”
- A custom IAM user policy limited to the Amazon S3 API for the Amazon Glacier archive “company-backup”.
- A custom IAM user policy limited to the Amazon S3 API in “company-backup”.
Answer D.
Explanation: Taking queue from the previous questions, this use case involves more granular permissions, hence IAM would be used here.
40. Can S3 be used with EC2 instances, if yes, how?
Yes, it can be used for instances with root devices backed by local instance storage. By using Amazon S3, developers have access to the same highly scalable, reliable, fast, inexpensive data storage infrastructure that Amazon uses to run its own global network of web sites. In order to execute systems in the Amazon EC2 environment, developers use the tools provided to load their Amazon Machine Images (AMIs) into Amazon S3 and to move them between Amazon S3 and Amazon EC2.
Another use case could be for websites hosted on EC2 to load their static content from S3.
For a detailed discussion on S3, please refer our S3 AWS blog.
41. A customer implemented AWS Storage Gateway with a gateway-cached volume at their main office. An event takes the link between the main and branch office offline. Which methods will enable the branch office to access their data?
- Restore by implementing a lifecycle policy on the Amazon S3 bucket.
- Make an Amazon Glacier Restore API call to load the files into another Amazon S3 bucket within four to six hours.
- Launch a new AWS Storage Gateway instance AMI in Amazon EC2, and restore from a gateway snapshot.
- Create an Amazon EBS volume from a gateway snapshot, and mount it to an Amazon EC2 instance.
Answer C.
Explanation: The fastest way to do it would be launching a new storage gateway instance. Why? Since time is the key factor which drives every business, troubleshooting this problem will take more time. Rather than we can just restore the previous working state of the storage gateway on a new instance.
42. When you need to move data over long distances using the internet, for instance across countries or continents to your Amazon S3 bucket, which method or service will you use?
- Amazon Glacier
- Amazon CloudFront
- Amazon Transfer Acceleration
- Amazon Snowball
Answer C.
Explanation: You would not use Snowball, because for now, the snowball service does not support cross region data transfer, and since, we are transferring across countries, Snowball cannot be used. Transfer Acceleration shall be the right choice here as it throttles your data transfer with the use of optimized network paths and Amazon’s content delivery network upto 300% compared to normal data transfer speed.
43. How can you speed up data transfer in Snowball?
The data transfer can be increased in the following way:
- By performing multiple copy operations at one time i.e. if the workstation is powerful enough, you can initiate multiple cp commands each from different terminals, on the same Snowball device.
- Copying from multiple workstations to the same snowball.
- Transferring large files or by creating a batch of small file, this will reduce the encryption overhead.
- Eliminating unnecessary hops i.e. make a setup where the source machine(s) and the snowball are the only machines active on the switch being used, this can hugely improve performance.
44. What’s the distinction between EBS and Instance Store?
EBS is a type of persistent storage that allows data to be recovered at a later time. When you save data to the EBS, it remains long after the EC2 instance has been terminated. Instance Store, on the other hand, is temporary storage that is physically tied to a host system. You cannot remove one instance and attach it to another using an Instance Store. Data in an Instance Store, unlike EBS, is lost if any instance is stopped or terminated.
45. How can you use EBS to automate EC2 backup?
To automate EC2 backups using EBS, perform the following steps:
Step 1. Get a list of instances and connect to AWS through API to get a list of Amazon EBS volumes that are associated to the instance locally.
Step 2. List each volume’s snapshots and give a retention time to each snapshot. Create a snapshot of each volume afterwards.
Step 3. Remove any snapshots that are older than the retention term.
Section 4: AWS Interview Questions for AWS VPC
46. What Is Amazon Virtual Private Cloud (VPC) and How Does It Work?
A VPC is the most efficient way to connect to your cloud services from within your own data centre. When you link your datacenter to the VPC that contains your instances, each instance is allocated a private IP address that can be accessed from your datacenter. As a result, you may use public cloud services as if they were on your own private network.
47. If you want to launch Amazon Elastic Compute Cloud (EC2) instances and assign each instance a predetermined private IP address you should:
- Launch the instance from a private Amazon Machine Image (AMI).
- Assign a group of sequential Elastic IP address to the instances.
- Launch the instances in the Amazon Virtual Private Cloud (VPC).
- Launch the instances in a Placement Group.
Answer C.
Explanation: The best way of connecting to your cloud resources (for ex- ec2 instances) from your own data center (for eg- private cloud) is a VPC. Once you connect your datacenter to the VPC in which your instances are present, each instance is assigned a private IP address which can be accessed from your datacenter. Hence, you can access your public cloud resources, as if they were on your own network.
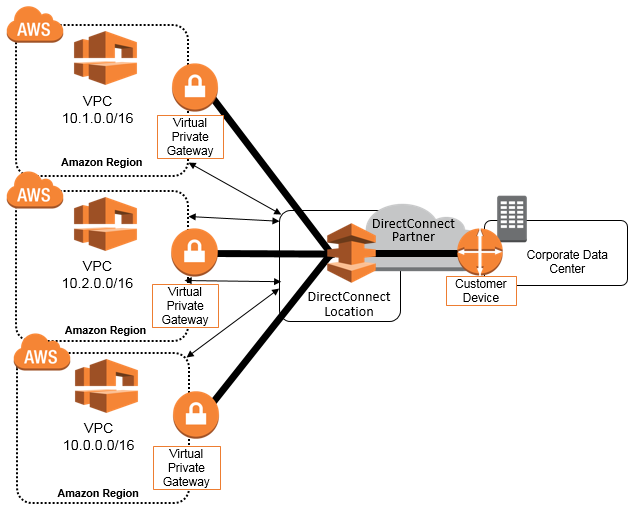
48. How do you connect multiple sites to a VPC?
If you have numerous VPN connections, you may use the AWS VPN CloudHub to encrypt communication across locations. Here’s an illustration of how to link different sites to a VPC:

49. What are some of the security products and features offered in VPC?
Here are some security products and features:
Security groups – serve as a firewall for EC2 instances, allowing you to regulate inbound and outgoing traffic at the instance level.
Network access control lists – It operates as a subnet-level firewall, managing inbound and outgoing traffic.
Flow logs – capture inbound and outgoing traffic from your VPC’s network interfaces.
50. How many Subnets are allowed in a VPC?
Each Amazon Virtual Private Cloud may support up to 200 Subnets (VPC).
51. Can I connect my corporate datacenter to the Amazon Cloud?
Yes, you can do this by establishing a VPN(Virtual Private Network) connection between your company’s network and your VPC (Virtual Private Cloud), this will allow you to interact with your EC2 instances as if they were within your existing network.
52. Is it possible to change the private IP addresses of an EC2 while it is running/stopped in a VPC?
Primary private IP address is attached with the instance throughout its lifetime and cannot be changed, however secondary private addresses can be unassigned, assigned or moved between interfaces or instances at any point.
53. Why do you make subnets?
- Because there is a shortage of networks
- To efficiently utilize networks that have a large no. of hosts.
- Because there is a shortage of hosts.
- To efficiently utilize networks that have a small no. of hosts.
Answer B.
Explanation: If there is a network which has a large no. of hosts, managing all these hosts can be a tedious job. Therefore we divide this network into subnets (sub-networks) so that managing these hosts becomes simpler.
54. Which of the following is true?
- You can attach multiple route tables to a subnet
- You can attach multiple subnets to a route table
- Both A and B
- None of these.
Answer B.
Explanation: Route Tables are used to route network packets, therefore in a subnet having multiple route tables will lead to confusion as to where the packet has to go. Therefore, there is only one route table in a subnet, and since a route table can have any no. of records or information, hence attaching multiple subnets to a route table is possible.
55. In CloudFront what happens when content is NOT present at an Edge location and a request is made to it?
- An Error “404 not found” is returned
- CloudFront delivers the content directly from the origin server and stores it in the cache of the edge location
- The request is kept on hold till content is delivered to the edge location
- The request is routed to the next closest edge location
Answer B.
Explanation: CloudFront is a content delivery system, which caches data to the nearest edge location from the user, to reduce latency. If data is not present at an edge location, the first time the data may get transferred from the original server, but from the next time, it will be served from the cached edge.
56. If I’m using Amazon CloudFront, can I use Direct Connect to transfer objects from my own data center?
Yes. Amazon CloudFront supports custom origins including origins from outside of AWS. With AWS Direct Connect, you will be charged with the respective data transfer rates.
57. If my AWS Direct Connect fails, will I lose my connectivity?
If a backup AWS Direct connect has been configured, in the event of a failure it will switch over to the second one. It is recommended to enable Bidirectional Forwarding Detection (BFD) when configuring your connections to ensure faster detection and failover. On the other hand, if you have configured a backup IPsec VPN connection instead, all VPC traffic will failover to the backup VPN connection automatically. Traffic to/from public resources such as Amazon S3 will be routed over the Internet. If you do not have a backup AWS Direct Connect link or a IPsec VPN link, then Amazon VPC traffic will be dropped in the event of a failure.
We will now look at the next section in our AWS interview questions and answers, the Amazon Database.
Section 5: AWS Interview Questions and Answers for Amazon Database
58. If I launch a standby RDS instance, will it be in the same Availability Zone as my primary?
- Only for Oracle RDS types
- Yes
- Only if it is configured at launch
- No
Answer D.
Explanation: No, since the purpose of having a standby instance is to avoid an infrastructure failure (if it happens), therefore the standby instance is stored in a different availability zone, which is a physically different independent infrastructure.
59. When would I prefer Provisioned IOPS over Standard RDS storage?
- If you have batch-oriented workloads
- If you use production online transaction processing (OLTP) workloads.
- If you have workloads that are not sensitive to consistent performance
- All of the above
Answer A.
Explanation: Provisioned IOPS deliver high IO rates but on the other hand it is expensive as well. Batch processing workloads do not require manual intervention they enable full utilization of systems, therefore a provisioned IOPS will be preferred for batch oriented workload.
60. Given that the RDS instance replica is not promoted as the master instance, how would you handle a situation in which the relational database engine routinely collapses as traffic to your RDS instances increases?
For managing high amounts of traffic, as well as creating manual or automatic snapshots to restore data if the RDS instance fails, a bigger RDS instance type is necessary.
61. Which scaling method would you recommend for RDS, and why?
Vertical scaling and horizontal scaling are the two forms of scaling. Vertical scaling allows you to scale up your master database vertically with the click of a button. A database can only be scaled vertically, and the RDS may be resized in 18 different ways. Horizontal scaling, on the other hand, is beneficial for copies. These are read-only replicas that can only be performed with Amazon Aurora.
62. How is Amazon RDS, DynamoDB and Redshift different?
- Amazon RDS is a database management service for relational databases, it manages patching, upgrading, backing up of data etc. of databases for you without your intervention. RDS is a Db management service for structured data only.
- DynamoDB, on the other hand, is a NoSQL database service, NoSQL deals with unstructured data.
- Redshift, is an entirely different service, it is a data warehouse product and is used in data analysis.
63. If I am running my DB Instance as a Multi-AZ deployment, can I use the standby DB Instance for read or write operations along with primary DB instance?
- Yes
- Only with MySQL based RDS
- Only for Oracle RDS instances
- No
Answer D.
Explanation: No, Standby DB instance cannot be used with primary DB instance in parallel, as the former is solely used for standby purposes, it cannot be used unless the primary instance goes down.
64. Your company’s branch offices are all over the world, they use a software with a multi-regional deployment on AWS, they use MySQL 5.6 for data persistence.
The task is to run an hourly batch process and read data from every region to compute cross-regional reports which will be distributed to all the branches. This should be done in the shortest time possible. How will you build the DB architecture in order to meet the requirements?
- For each regional deployment, use RDS MySQL with a master in the region and a read replica in the HQ region
- For each regional deployment, use MySQL on EC2 with a master in the region and send hourly EBS snapshots to the HQ region
- For each regional deployment, use RDS MySQL with a master in the region and send hourly RDS snapshots to the HQ region
- For each regional deployment, use MySQL on EC2 with a master in the region and use S3 to copy data files hourly to the HQ region
Answer A.
Explanation: For this we will take an RDS instance as a master, because it will manage our database for us and since we have to read from every region, we’ll put a read replica of this instance in every region where the data has to be read from. Option C is not correct since putting a read replica would be more efficient than putting a snapshot, a read replica can be promoted if needed to an independent DB instance, but with a Db snapshot it becomes mandatory to launch a separate DB Instance.
65. Can I run more than one DB instance for Amazon RDS for free?
Yes. You can run more than one Single-AZ Micro database instance, that too for free! However, any use exceeding 750 instance hours, across all Amazon RDS Single-AZ Micro DB instances, across all eligible database engines and regions, will be billed at standard Amazon RDS prices. For example: if you run two Single-AZ Micro DB instances for 400 hours each in a single month, you will accumulate 800 instance hours of usage, of which 750 hours will be free. You will be billed for the remaining 50 hours at the standard Amazon RDS price.
For a detailed discussion on this topic, please refer our RDS AWS blog.
66. Which AWS services will you use to collect and process e-commerce data for near real-time analysis?
- Amazon ElastiCache
- Amazon DynamoDB
- Amazon Redshift
- Amazon Elastic MapReduce
Answer B,C.
Explanation: DynamoDB is a fully managed NoSQL database service. DynamoDB, therefore can be fed any type of unstructured data, which can be data from e-commerce websites as well, and later, an analysis can be done on them using Amazon Redshift. We are not using Elastic MapReduce, since a near real time analyses is needed.
67. Can I retrieve only a specific element of the data, if I have a nested JSON data in DynamoDB?
Yes. When using the GetItem, BatchGetItem, Query or Scan APIs, you can define a Projection Expression to determine which attributes should be retrieved from the table. Those attributes can include scalars, sets, or elements of a JSON document.
68. A company is deploying a new two-tier web application in AWS. The company has limited staff and requires high availability, and the application requires complex queries and table joins. Which configuration provides the solution for the company’s requirements?
- MySQL Installed on two Amazon EC2 Instances in a single Availability Zone
- Amazon RDS for MySQL with Multi-AZ
- Amazon ElastiCache
- Amazon DynamoDB
Answer D.
Explanation: DynamoDB has the ability to scale more than RDS or any other relational database service, therefore DynamoDB would be the apt choice.
69. What happens to my backups and DB Snapshots if I delete my DB Instance?
When you delete a DB instance, you have an option of creating a final DB snapshot, if you do that you can restore your database from that snapshot. RDS retains this user-created DB snapshot along with all other manually created DB snapshots after the instance is deleted, also automated backups are deleted and only manually created DB Snapshots are retained.
70. Which of the following use cases are suitable for Amazon DynamoDB? Choose 2 answers
- Managing web sessions.
- Storing JSON documents.
- Storing metadata for Amazon S3 objects.
- Running relational joins and complex updates.
Answer C,D.
Explanation: If all your JSON data have the same fields eg [id,name,age] then it would be better to store it in a relational database, the metadata on the other hand is unstructured, also running relational joins or complex updates would work on DynamoDB as well.
71. How can I load my data to Amazon Redshift from different data sources like Amazon RDS, Amazon DynamoDB and Amazon EC2?
You can load the data in the following two ways:
- You can use the COPY command to load data in parallel directly to Amazon Redshift from Amazon EMR, Amazon DynamoDB, or any SSH-enabled host.
- AWS Data Pipeline provides a high performance, reliable, fault tolerant solution to load data from a variety of AWS data sources. You can use AWS Data Pipeline to specify the data source, desired data transformations, and then execute a pre-written import script to load your data into Amazon Redshift.
72. What is an Amazon RDS maintenance window? Will your database instance be available during maintenance?
You may plan DB instance updates, database engine version upgrades, and software patching using the RDS maintenance window. Only upgrades for security and durability are scheduled automatically. The maintenance window is set to 30 minutes by default, and the DB instance will remain active throughout these events, but with somewhat reduced performance.
73. Your application has to retrieve data from your user’s mobile every 5 minutes and the data is stored in DynamoDB, later every day at a particular time the data is extracted into S3 on a per user basis and then your application is later used to visualize the data to the user. You are asked to optimize the architecture of the backend system to lower cost, what would you recommend?
- Create a new Amazon DynamoDB (able each day and drop the one for the previous day after its data is on Amazon S3.
- Introduce an Amazon SQS queue to buffer writes to the Amazon DynamoDB table and reduce provisioned write throughput.
- Introduce Amazon Elasticache to cache reads from the Amazon DynamoDB table and reduce provisioned read throughput.
- Write data directly into an Amazon Redshift cluster replacing both Amazon DynamoDB and Amazon S3.
Answer C.
Explanation: Since our work requires the data to be extracted and analyzed, to optimize this process a person would use provisioned IO, but since it is expensive, using a ElastiCache memoryinsread to cache the results in the memory can reduce the provisioned read throughput and hence reduce cost without affecting the performance.
74. You are running a website on EC2 instances deployed across multiple Availability Zones with a Multi-AZ RDS MySQL Extra Large DB Instance. The site performs a high number of small reads and writes per second and relies on an eventual consistency model. After comprehensive tests you discover that there is read contention on RDS MySQL. Which are the best approaches to meet these requirements? (Choose 2 answers)
- Deploy ElastiCache in-memory cache running in each availability zone
- Implement sharding to distribute load to multiple RDS MySQL instances
- Increase the RDS MySQL Instance size and Implement provisioned IOPS
- Add an RDS MySQL read replica in each availability zone
Answer A,C.
Explanation: Since it does a lot of read writes, provisioned IO may become expensive. But we need high performance as well, therefore the data can be cached using ElastiCache which can be used for frequently reading the data. As for RDS since read contention is happening, the instance size should be increased and provisioned IO should be introduced to increase the performance.
75. A startup is running a pilot deployment of around 100 sensors to measure street noise and air quality in urban areas for 3 months. It was noted that every month around 4GB of sensor data is generated. The company uses a load balanced auto scaled layer of EC2 instances and a RDS database with 500 GB standard storage. The pilot was a success and now they want to deploy at least 100K sensors which need to be supported by the backend. You need to store the data for at least 2 years to analyze it. Which setup of the following would you prefer?
- Add an SQS queue to the ingestion layer to buffer writes to the RDS instance
- Ingest data into a DynamoDB table and move old data to a Redshift cluster
- Replace the RDS instance with a 6 node Redshift cluster with 96TB of storage
- Keep the current architecture but upgrade RDS storage to 3TB and 10K provisioned IOPS
Answer C.
Explanation: A Redshift cluster would be preferred because it easy to scale, also the work would be done in parallel through the nodes, therefore is perfect for a bigger workload like our use case. Since each month 4 GB of data is generated, therefore in 2 year, it should be around 96 GB. And since the servers will be increased to 100K in number, 96 GB will approximately become 96TB. Hence option C is the right answer.
Section 6: AWS Interview Questions and Answers for AWS Auto Scaling, AWS Load Balancer
76. Suppose you have an application where you have to render images and also do some general computing. From the following services which service will best fit your need?
- Classic Load Balancer
- Application Load Balancer
- Both of them
- None of these
Answer B.
Explanation: You will choose an application load balancer, since it supports path based routing, which means it can take decisions based on the URL, therefore if your task needs image rendering it will route it to a different instance, and for general computing it will route it to a different instance.
77. What is the difference between Scalability and Elasticity?
Scalability is the ability of a system to increase its hardware resources to handle the increase in demand. It can be done by increasing the hardware specifications or increasing the processing nodes.
Elasticity is the ability of a system to handle increase in the workload by adding additional hardware resources when the demand increases(same as scaling) but also rolling back the scaled resources, when the resources are no longer needed. This is particularly helpful in Cloud environments, where a pay per use model is followed.
78. How can an existing instance be added to a new Auto Scaling group?
To add an existing instance to a new Auto Scaling group, follow these steps:
Step1. Launch the EC2 console.
Step2. Select your instance from the list of Instances.
Step3. Navigate to Actions -> Instance Settings -> Join the Auto Scaling Group
Step4. Choose a new Auto Scaling group.
Step5. Join this group to the Instance.
Step6. If necessary, modify the instance.
Step7. Once completed, the instance may be successfully added to a new Auto Scaling group.
79. How will you change the instance type for instances which are running in your application tier and are using Auto Scaling. Where will you change it from the following areas?
- Auto Scaling policy configuration
- Auto Scaling group
- Auto Scaling tags configuration
- Auto Scaling launch configuration
Answer D.
Explanation: Auto scaling tags configuration, is used to attach metadata to your instances, to change the instance type you have to use auto scaling launch configuration.
80. You have a content management system running on an Amazon EC2 instance that is approaching 100% CPU utilization. Which option will reduce load on the Amazon EC2 instance?
- Create a load balancer, and register the Amazon EC2 instance with it
- Create a CloudFront distribution, and configure the Amazon EC2 instance as the origin
- Create an Auto Scaling group from the instance using the CreateAutoScalingGroup action
- Create a launch configuration from the instance using the CreateLaunchConfigurationAction
Answer A.
Explanation:Creating alone an autoscaling group will not solve the issue, until you attach a load balancer to it. Once you attach a load balancer to an autoscaling group, it will efficiently distribute the load among all the instances. Option B – CloudFront is a CDN, it is a data transfer tool therefore will not help reduce load on the EC2 instance. Similarly the other option – Launch configuration is a template for configuration which has no connection with reducing loads.
81. When should I use a Classic Load Balancer and when should I use an Application load balancer?
A Classic Load Balancer is ideal for simple load balancing of traffic across multiple EC2 instances, while an Application Load Balancer is ideal for microservices or container-based architectures where there is a need to route traffic to multiple services or load balance across multiple ports on the same EC2 instance.
For a detailed discussion on Auto Scaling and Load Balancer, please refer our EC2 AWS blog.
82. What does Connection draining do?
- Terminates instances which are not in use.
- Re-routes traffic from instances which are to be updated or failed a health check.
- Re-routes traffic from instances which have more workload to instances which have less workload.
- Drains all the connections from an instance, with one click.
Answer B.
Explanation: Connection draining is a service under ELB which constantly monitors the health of the instances. If any instance fails a health check or if any instance has to be patched with a software update, it pulls all the traffic from that instance and re routes them to other instances.
83. When an instance is unhealthy, it is terminated and replaced with a new one, which of the following services does that?
- Sticky Sessions
- Fault Tolerance
- Connection Draining
- Monitoring
Answer B.
Explanation: When ELB detects that an instance is unhealthy, it starts routing incoming traffic to other healthy instances in the region. If all the instances in a region becomes unhealthy, and if you have instances in some other availability zone/region, your traffic is directed to them. Once your instances become healthy again, they are re routed back to the original instances.
84. What are lifecycle hooks used for in AutoScaling?
- They are used to do health checks on instances
- They are used to put an additional wait time to a scale in or scale out event.
- They are used to shorten the wait time to a scale in or scale out event
- None of these
Answer B.
Explanation: Lifecycle hooks are used for putting wait time before any lifecycle action i.e launching or terminating an instance happens. The purpose of this wait time, can be anything from extracting log files before terminating an instance or installing the necessary softwares in an instance before launching it.
85. A user has setup an Auto Scaling group. Due to some issue the group has failed to launch a single instance for more than 24 hours. What will happen to Auto Scaling in this condition?
- Auto Scaling will keep trying to launch the instance for 72 hours
- Auto Scaling will suspend the scaling process
- Auto Scaling will start an instance in a separate region
- The Auto Scaling group will be terminated automatically
Answer B.
Explanation: Auto Scaling allows you to suspend and then resume one or more of the Auto Scaling processes in your Auto Scaling group. This can be very useful when you want to investigate a configuration problem or other issue with your web application, and then make changes to your application, without triggering the Auto Scaling process.
Section 7: AWS Interview Questions for CloudTrail, Route 53
86. What is Cloudtrail, and how does it interact with Route 53?
CloudTrail is a service that logs every request made to the Amazon Route 53 API by an AWS account, including those made by IAM users. CloudTrail stores these requests’ log files to an Amazon S3 bucket. CloudTrail collects data on all requests. CloudTrail log files contain information that may be used to discover which requests were submitted to Amazon Route 53, the IP address from which the request was sent, who issued the request, when it was sent, and more.
87. How does AWS configuration interact with AWS CloudTrail?
AWS CloudTrail logs user API activity on your account and provides you with access to the data. CloudTrail provides detailed information on API activities such as the caller’s identity, the time of the call, request arguments, and response elements. AWS Config, on the other hand, saves point-in-time configuration parameters for your AWS resources as Configuration Items (CIs).
A CI may be used to determine what your AWS resource looks like at any given time. Using CloudTrail, on the other hand, you can instantly determine who made an API request to alter the resource. Cloud Trail may also be used to determine if a security group was wrongly setup.
88. You have an EC2 Security Group with several running EC2 instances. You changed the Security Group rules to allow inbound traffic on a new port and protocol, and then launched several new instances in the same Security Group. The new rules apply:
- Immediately to all instances in the security group.
- Immediately to the new instances only.
- Immediately to the new instances, but old instances must be stopped and restarted before the new rules apply.
- To all instances, but it may take several minutes for old instances to see the changes.
Answer A.
Explanation: Any rule specified in an EC2 Security Group applies immediately to all the instances, irrespective of when they are launched before or after adding a rule.
89. To create a mirror image of your environment in another region for disaster recovery, which of the following AWS resources do not need to be recreated in the second region? ( Choose 2 answers )
- Route 53 Record Sets
- Elastic IP Addresses (EIP)
- EC2 Key Pairs
- Launch configurations
- Security Groups
Answer A.
Explanation: Route 53 record sets are common assets therefore there is no need to replicate them, since Route 53 is valid across regions
90. A customer wants to capture all client connection information from his load balancer at an interval of 5 minutes, which of the following options should he choose for his application?
- Enable AWS CloudTrail for the loadbalancer.
- Enable access logs on the load balancer.
- Install the Amazon CloudWatch Logs agent on the load balancer.
- Enable Amazon CloudWatch metrics on the load balancer.
Answer A.
Explanation: AWS CloudTrail provides inexpensive logging information for load balancer and other AWS resources This logging information can be used for analyses and other administrative work, therefore is perfect for this use case.
91. A customer wants to track access to their Amazon Simple Storage Service (S3) buckets and also use this information for their internal security and access audits. Which of the following will meet the Customer requirement?
- Enable AWS CloudTrail to audit all Amazon S3 bucket access.
- Enable server access logging for all required Amazon S3 buckets.
- Enable the Requester Pays option to track access via AWS Billing
- Enable Amazon S3 event notifications for Put and Post.
Answer A.
Explanation: AWS CloudTrail has been designed for logging and tracking API calls. Also this service is available for storage, therefore should be used in this use case.
92. Which of the following are true regarding AWS CloudTrail? (Choose 2 answers)
- CloudTrail is enabled globally
- CloudTrail is enabled on a per-region and service basis
- Logs can be delivered to a single Amazon S3 bucket for aggregation.
- CloudTrail is enabled for all available services within a region.
Answer B,C.
Explanation: Cloudtrail is not enabled for all the services and is also not available for all the regions. Therefore option B is correct, also the logs can be delivered to your S3 bucket, hence C is also correct.
93. What happens if CloudTrail is turned on for my account but my Amazon S3 bucket is not configured with the correct policy?
CloudTrail files are delivered according to S3 bucket policies. If the bucket is not configured or is misconfigured, CloudTrail might not be able to deliver the log files.
94. How do I transfer my existing domain name registration to Amazon Route 53 without disrupting my existing web traffic?
You will need to get a list of the DNS record data for your domain name first, it is generally available in the form of a “zone file” that you can get from your existing DNS provider. Once you receive the DNS record data, you can use Route 53’s Management Console or simple web-services interface to create a hosted zone that will store your DNS records for your domain name and follow its transfer process. It also includes steps such as updating the nameservers for your domain name to the ones associated with your hosted zone. For completing the process you have to contact the registrar with whom you registered your domain name and follow the transfer process. As soon as your registrar propagates the new name server delegations, your DNS queries will start to get answered.
95. What services are available for implementing a centralised logging solution?
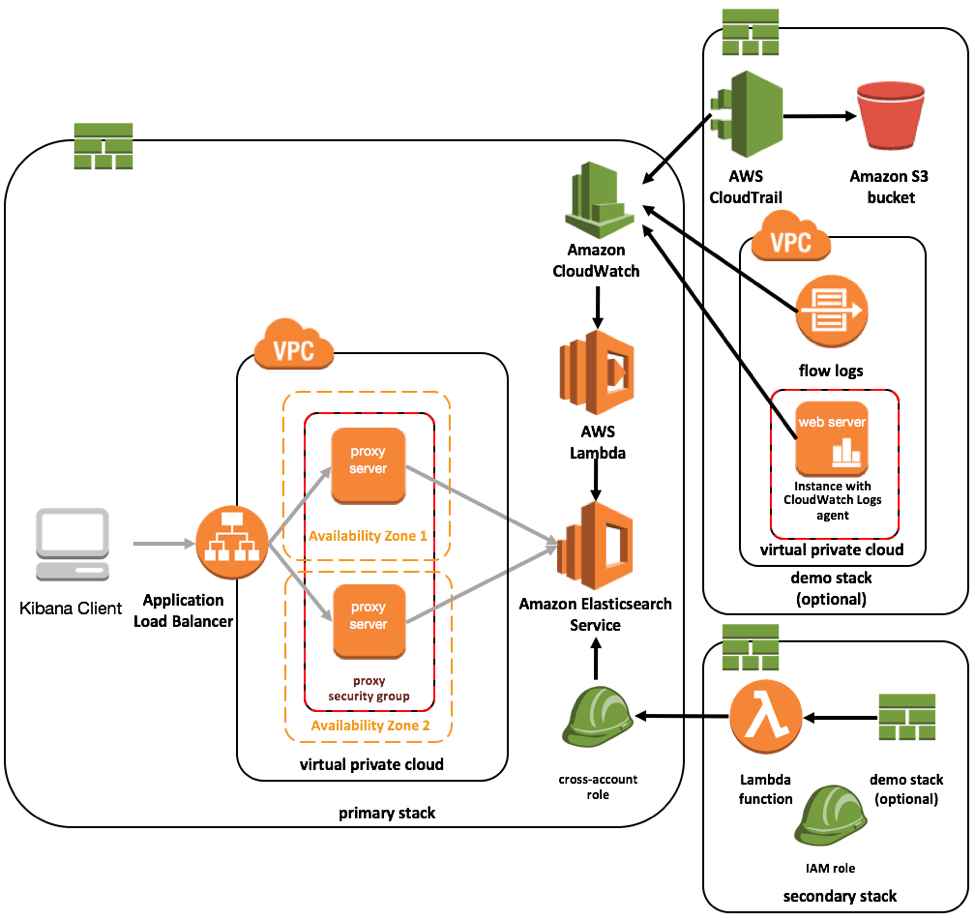
The most important services you may utilise are Amazon CloudWatch Logs, which you can store in Amazon S3 and then display using Amazon Elastic Search. To transfer data from Amazon S3 to Amazon ElasticSearch, you can utilise Amazon Kinesis Firehose.

Section 8: AWS Interview Questions for AWS SQS, AWS SNS, AWS SES, AWS ElasticBeanstalk
96. WHAT EXACTLY ARE SNS AND SQS?
Ans: Amazon Simple Notification Service (SNS) is a web service that manages user notifications sent from any cloud platform. From any cloud platform, manage and distribute messages or notifications to users and consumers.
Amazon Simple Queue Service (SQS) administers the queue service, which allows users to move data whether it is running or active.
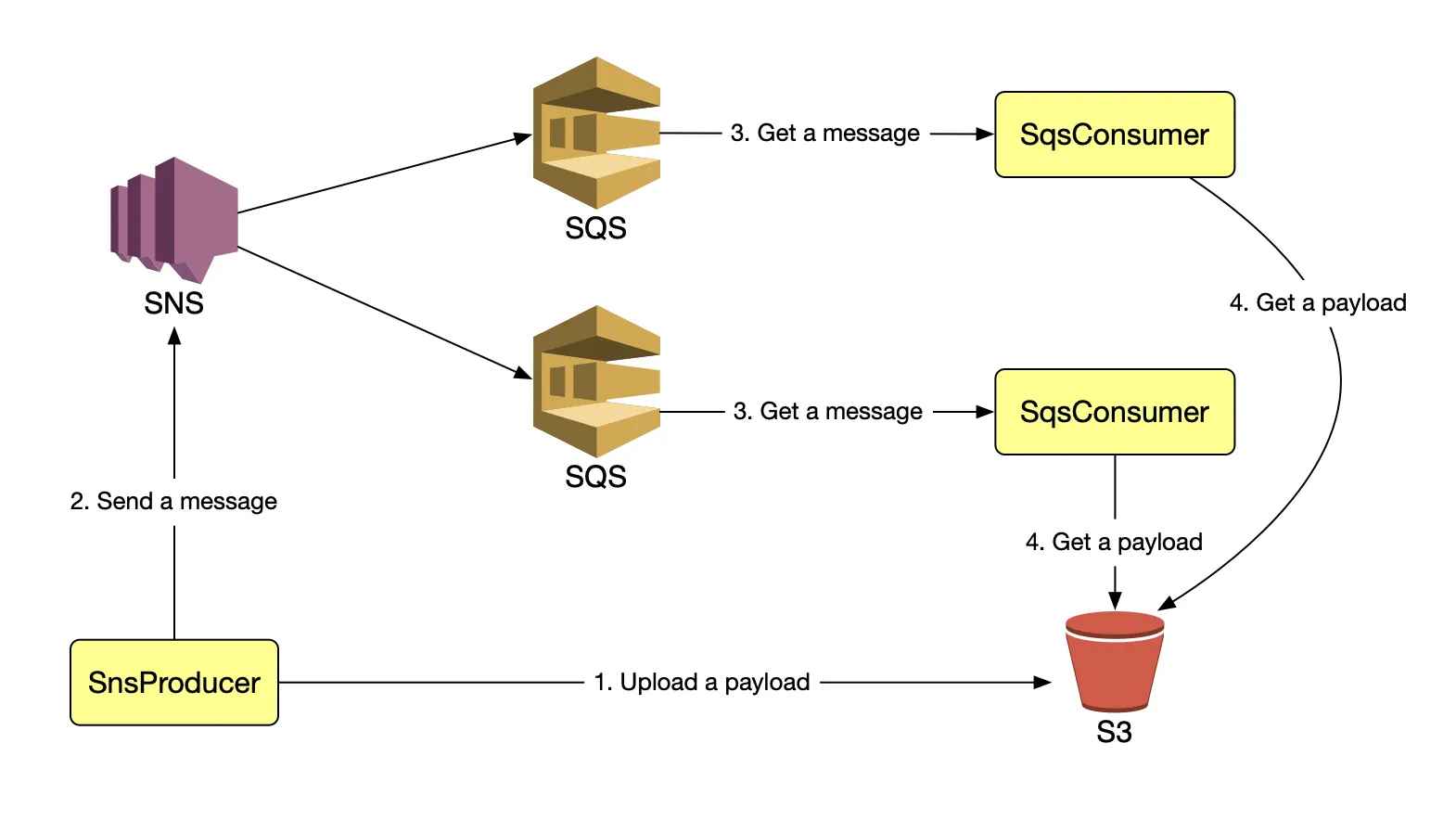

- Elastic Beanstalk
- Lambda
- Opsworks
- CloudFormation
Answer B.
Explanation: Lambda is used for running server-less applications. It can be used to deploy functions triggered by events. When we say serverless, we mean without you worrying about the computing resources running in the background. It is not designed for creating applications which are publicly accessed.
98. What distinguishes AWS CludFormation from AWS Elastic Beanstalk?
The following are some distinctions between AWS CloudFormation and AWS Elastic Beanstalk:
AWS CloudFormation assists you in provisioning and describing all infrastructure resources in your cloud environment. AWS Elastic Beanstalk, on the other hand, provides an environment that makes it simple to install and execute cloud applications.
AWS CloudFormation meets the infrastructure requirements of a wide range of applications, including legacy applications and existing corporate applications. AWS Elastic Beanstalk, on the other hand, is integrated with developer tools to assist you in managing the lifespan of your applications.
99. How does Elastic Beanstalk apply updates?
- By having a duplicate ready with updates before swapping.
- By updating on the instance while it is running
- By taking the instance down in the maintenance window
- Updates should be installed manually
Answer A.
Explanation: Elastic Beanstalk prepares a duplicate copy of the instance, before updating the original instance, and routes your traffic to the duplicate instance, so that, incase your updated application fails, it will switch back to the original instance, and there will be no downtime experienced by the users who are using your application.
100. What happens if my application in Beanstalk stops responding to requests?
AWS Beanstalk apps provide a built-in method for preventing infrastructure problems. If an Amazon EC2 instance dies for whatever reason, Beanstalk will instantly start a new instance using Auto Scaling. Beanstalk can detect if your application is not responding to the custom link.
101. How is AWS Elastic Beanstalk different than AWS OpsWorks?
AWS Elastic Beanstalk is an application management platform while OpsWorks is a configuration management platform. BeanStalk is an easy to use service which is used for deploying and scaling web applications developed with Java, .Net, PHP, Node.js, Python, Ruby, Go and Docker. Customers upload their code and Elastic Beanstalk automatically handles the deployment. The application will be ready to use without any infrastructure or resource configuration.
In contrast, AWS Opsworks is an integrated configuration management platform for IT administrators or DevOps engineers who want a high degree of customization and control over operations.
102. What happens if my application stops responding to requests in beanstalk?
AWS Beanstalk applications have a system in place for avoiding failures in the underlying infrastructure. If an Amazon EC2 instance fails for any reason, Beanstalk will use Auto Scaling to automatically launch a new instance. Beanstalk can also detect if your application is not responding on the custom link, even though the infrastructure appears healthy, it will be logged as an environmental event( e.g a bad version was deployed) so you can take an appropriate action.
For a detailed discussion on this topic, please refer Lambda AWS blog.
Section 9: AWS Interview Questions and Answers for AWS OpsWorks, AWS KMS
103. How is AWS OpsWorks different than AWS CloudFormation?
OpsWorks and CloudFormation both support application modelling, deployment, configuration, management and related activities. Both support a wide variety of architectural patterns, from simple web applications to highly complex applications. AWS OpsWorks and AWS CloudFormation differ in abstraction level and areas of focus.
AWS CloudFormation is a building block service which enables customer to manage almost any AWS resource via JSON-based domain specific language. It provides foundational capabilities for the full breadth of AWS, without prescribing a particular model for development and operations. Customers define templates and use them to provision and manage AWS resources, operating systems and application code.
In contrast, AWS OpsWorks is a higher level service that focuses on providing highly productive and reliable DevOps experiences for IT administrators and ops-minded developers. To do this, AWS OpsWorks employs a configuration management model based on concepts such as stacks and layers, and provides integrated experiences for key activities like deployment, monitoring, auto-scaling, and automation. Compared to AWS CloudFormation, AWS OpsWorks supports a narrower range of application-oriented AWS resource types including Amazon EC2 instances, Amazon EBS volumes, Elastic IPs, and Amazon CloudWatch metrics.
104. A firm seeking to migrate to the AWS Cloud wants to use its existing Chef recipes for infrastructure configuration management. Which AWS service would be best for this need?
- AWS Elastic Load Balancer
- AWS Elastic Beanstalk
- AWS OpsWorks
- AWS Inspector
Answer C.
Explanation: AWS OpsWorks is a configuration management solution that allows you to use Puppet or Chef to setup and run applications in a cloud organisation. AWS OpsWorks Stacks and AWS OpsWorks for Chef Automate allow you to leverage Chefcookbooks and solutions for configuration management, whereas AWS OpsWorks for Puppet Enterprise allows you to set up an AWS Puppet Enterprise master server. Puppet provides a suite of tools for enforcing desirable infrastructure states and automating on-demand operations.
105. I created a key in Oregon region to encrypt my data in North Virginia region for security purposes. I added two users to the key and an external AWS account. I wanted to encrypt an object in S3, so when I tried, the key that I just created was not listed. What could be the reason?
- External aws accounts are not supported.
- AWS S3 cannot be integrated KMS.
- The Key should be in the same region.
- New keys take some time to reflect in the list.
Answer C.
Explanation: The key created and the data to be encrypted should be in the same region. Hence the approach taken here to secure the data is incorrect.
106. A company’s demand in AWS is for a mound- grounded paradigm for its coffers. Different heaps are needed for the Development and product surroundings. Which of the following styles may be utilised to meet this demand?
- A. EC2 markers to define different mound layers for your coffers.
- In DynamoD, define the metadata for the various levels.
- Define the various tiers for your operation using AWS OpsWorks.
- Define the different levels for your business using AWS Config.
Answer C.
Explanation: The OpsWorks service can meet the need. This need is supported by the AWS attestation listed below AWS OpsWorks Stacks allows you to manage AWS and on- demesne apps and waiters. You may represent your operation as a mound with several layers similar as cargo balancing, database, and operation garçon using OpsWorks Stacks. In each league, you may emplace and configure Amazon EC2 cases or link fresh coffers similar as Amazon RDS databases.
107. A company needs to monitor the read and write IOPS for their AWS MySQL RDS instance and send real-time alerts to their operations team. Which AWS services can accomplish this?
- Amazon Simple Email Service
- Amazon CloudWatch
- Amazon Simple Queue Service
- Amazon Route 53
Answer B.
Explanation: Amazon CloudWatch is a cloud monitoring tool and hence this is the right service for the mentioned use case. The other options listed here are used for other purposes for example route 53 is used for DNS services, therefore CloudWatch will be the apt choice.
108. What happens when one of the resources in a stack cannot be created successfully in AWS OpsWorks?
When an event like this occurs, the “automatic rollback on error” feature is enabled, which causes all the AWS resources which were created successfully till the point where the error occurred to be deleted. This is helpful since it does not leave behind any erroneous data, it ensures the fact that stacks are either created fully or not created at all. It is useful in events where you may accidentally exceed your limit of the no. of Elastic IP addresses or maybe you may not have access to an EC2 AMI that you are trying to run etc.
109. What automation tools can you use to spinup servers?
Any of the following tools can be used:
- Roll-your-own scripts, and use the AWS API tools. Such scripts could be written in bash, perl or other language of your choice.
- Use a configuration management and provisioning tool like puppet or its successor Opscode Chef. You can also use a tool like Scalr.
- Use a managed solution such as Rightscale.
Overwhelmed with all these questions? Below are the top technologies to learn in 2023

We at Edureka are here to help you with every step on your journey, to becoming an AWS Solution Architect; therefore besides the AWS Interview Questions and answers, we have come up with a curriculum that covers exactly what you would need to crack the Solution Architect Exam! You can have a look at the course details from the AWS training in Chennai.
I hope you benefitted from these AWS Interview Questions. The topics that you learned in this blog are the most sought-after skill sets that recruiters look for in an AWS Solution Architect Professional. I have tried touching up on AWS interview questions and answers for freshers and for people with 3-5 years of experience. However, for a more detailed study on AWS, you can refer our AWS Tutorial.
Got a question for us? Please mention it in the comments section of this AWS Interview Questions and we will get back to you.
Related Posts: